- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
PlantCLEF 2017

Usage scenario
Crowdsourced initiatives such as iNaturalist, Tela Botanica, or iSpot produce big amounts of biodiversity data that are intended in the long term, to renew today’s ecological monitoring approaches with much more timely and cheaper raw input data. At the same time, with the recent advances in computer vision, we see the emergence of more and more effective mobile search tools allowing to set-up large scale data collection platforms such as the popular Pl@ntNet initiative. This platform is already being used by more than 500K people who produce tens of thousands of validated plant observations each year. This explicitly shared and validated data is only the tip of the iceberg. The real potential relies on the millions of raw image queries submitted by the users of the mobile application for which there is no human validation. People make such requests to get information on a plant along a hike or something they find in their garden but not know anything about. Allowing the exploitation of such contents in a fully automatic way could scale up the world-wide collection of plant observations by several orders of magnitude, and potentially bring a valuable resource for ecological monitoring studies.
Data collection and evaluated challenge
The test data to be analyzed is a large sample of the raw query images submitted by the users of the mobile application Pl@ntNet (iPhone & Androïd), covering a large number of wild plant species mostly coming from the Western Europe Flora and the North American Flora, but also plant species used all around the world as cultivated or ornamental plants, or even endangered species precisely because of their non-regulated commerce.
As training data, we will provide two main sets based both on the same list of 10 000 plant species:
- a “trusted” training set based on the online collaborative Encyclopedia Of Life (EoL)
- a “noisy” training set built through from web crawlers (more exactly from google and bing image search results)
The main idea of providing both datasets is to evaluate to what extent machine learning and computer vision techniques can learn from noisy data compared to trusted data (as usually done in supervised classification).
Pictures of EoL are themselves coming from several public databases (such as Wikimedia, iNaturalist, Flickr) or from some Institutions or less formal websites dedicated to botany. All the pictures can be potentially revised and rated on the EOL website.
On the other side, the noisy training set will contain more images for a lot of species, but with several type and level of noises which are basically impossible to automatically entirely control and clean: a picture can be associated to the wrong species but the correct genus or family, a picture can be a portrait of a botanist working on the species, the pictures can be associated to the correct species but be a drawing or an herbarium sheet of a dry specimen, etc.
Task description
The task will consist of automatically detecting in the Pl@ntNet query images, specimens of plants belonging to the provided training data. More practically, the run file to be submitted has to contain as much lines as the number of predictions, each prediction being composed of an ObservationId (the identifier of a specimen that can be itself composed of several images), a ClassId, a Probability and a Rank (used in case of equal probabilities). Each line should have the following format:
<ObservationId;ClassId;Probability;Rank>
where Probability is a scalar in [0,1] representing the confidence of the system in that recognition (Probability=1 means that the system is very confident) and Rank is an integer between in [1:100] (i.e. one single test ObservationId might be associated to at most 100 species predictions).
Here is a short fake run example respecting this format for only 3 observations:
myTeam_PlantCLEF2017_run2.txt
Each participating group is allowed to submit up to 4 runs built from different methods. Semi-supervised, interactive or crowdsourced approaches are allowed but will be compared independently from fully automatic methods. Any human assistance in the processing of the test queries has therefore to be signaled in the submitted runs.
We encourage participants to compare the use of the noisy and the trusted training setswithin their runs and it will be required to mention which training set were used in each run (EOL, WEB or EOL+WEB). Please note that the two training sets can have some common pictures (even if we excluded EOL domain from the web crawl).
Participants are allowed to use complementary training data (e.g. for pre-training purposes) but at the condition that (i) the experiment is entirely re-produceable, i.e. that the used external resource is clearly referenced and accessible to any other research group in the world, (ii) the use of external training data or not is mentioned for each run, and (iii) the additional resource does not contain any of the test observations.
Metric
The used metric will be the Mean Reciprocal Rank (MRR). The MRR is a statistic measure for evaluating any process that produces a list of possible responses to a sample of queries ordered by probability of correctness. The reciprocal rank of a query response is the multiplicative inverse of the rank of the first correct answer. The MRR is the average of the reciprocal ranks for the whole test set:
where |Q| is the total number of query occurrences in the test set.

Results
A total of 8 participating groups submitted 29 runs. Thanks to all of you for your efforts and your constructive feedbacks regarding the organization!
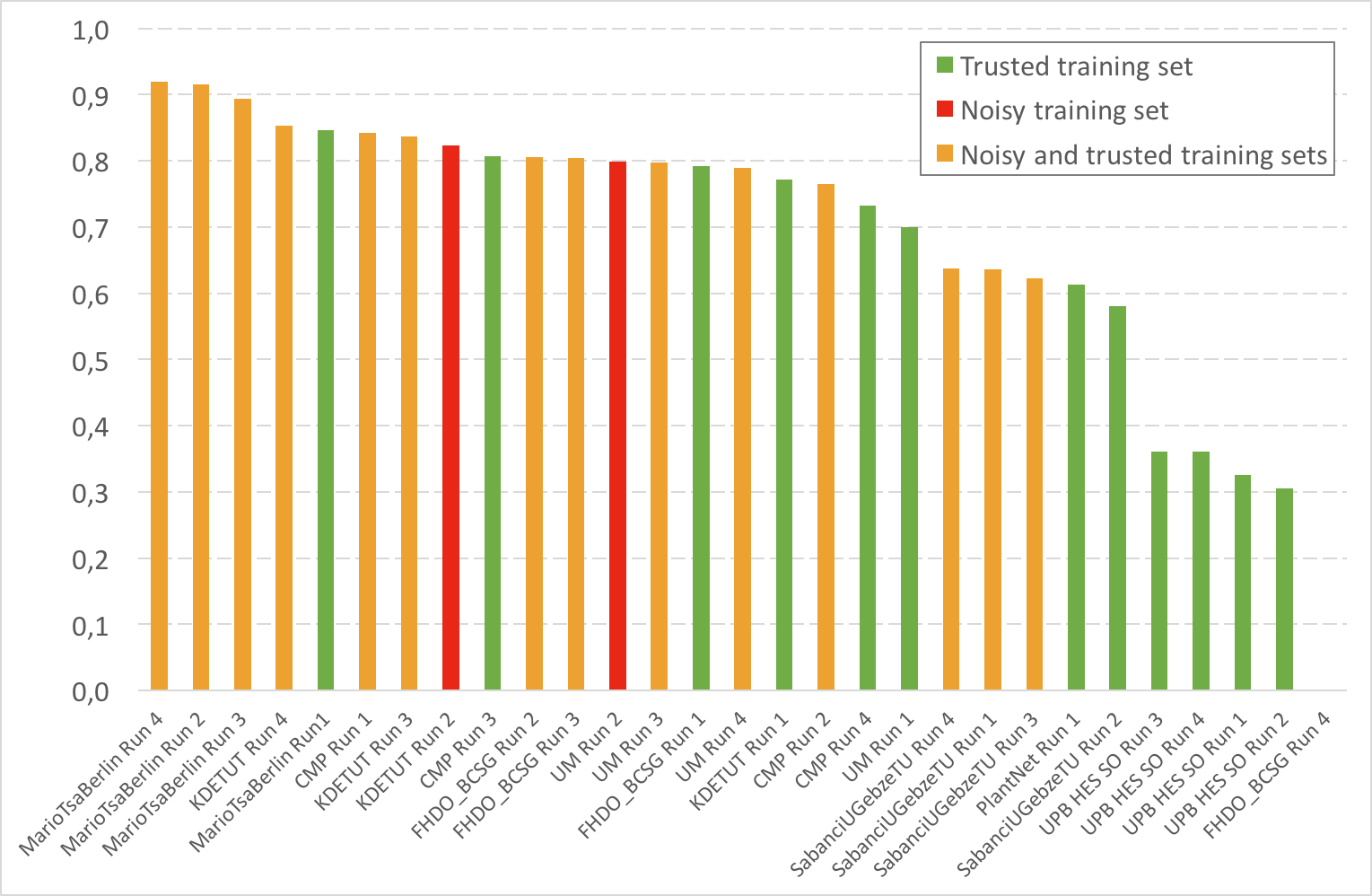
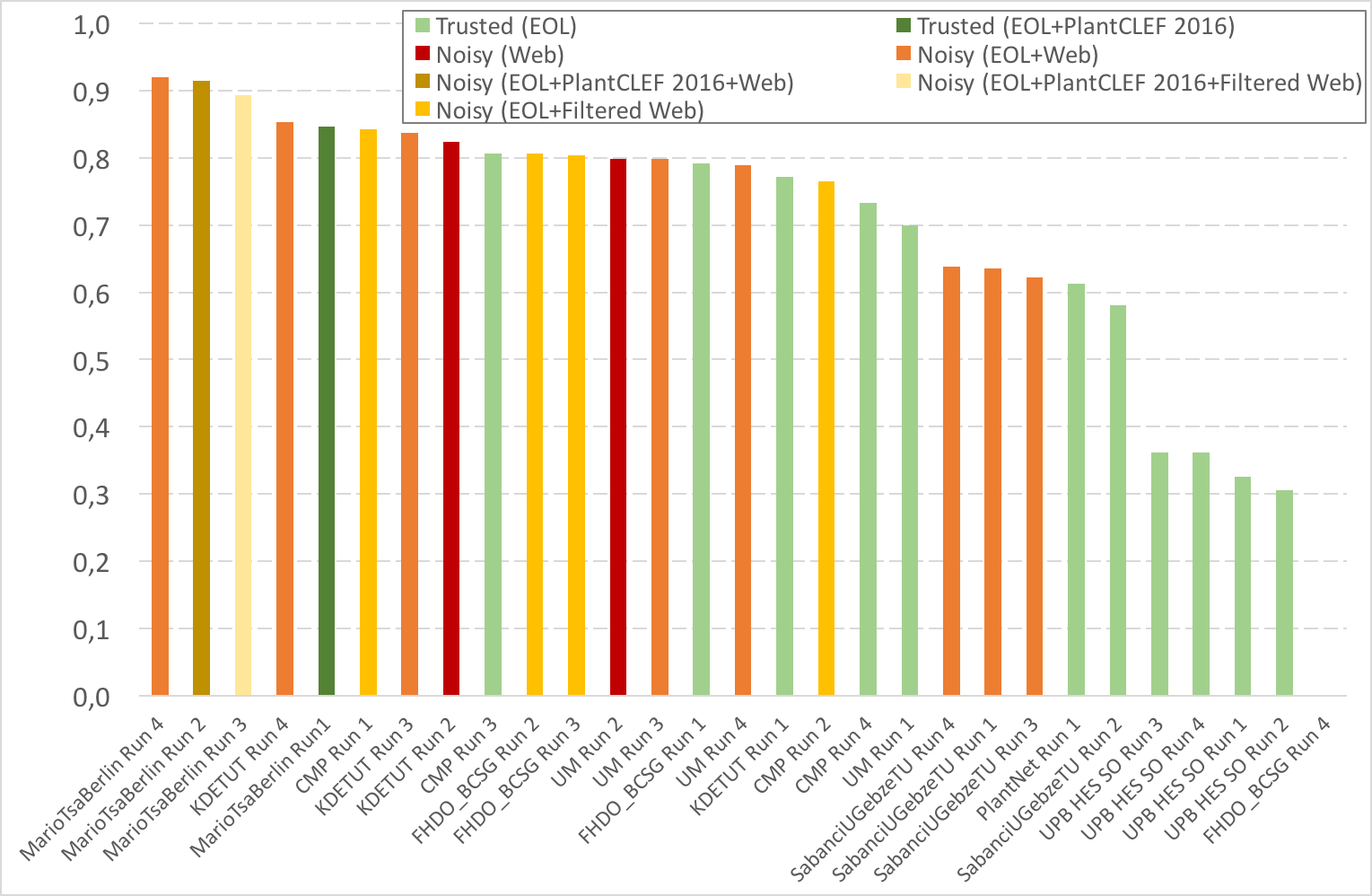
The following table and figure give the results and report with more details which dataset(s) were used as training set(s):
- E: trusted training set EOL
- P: trusted training set PlantCLEF 2016
- W: noisy training set Web
- FW: Filtered noisy training Web)
| Run Name | Run | Score | Train | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Trusted | Trusted | Noisy | Noisy | Noisy | Noisy | Noisy | Top1 | Top5 | |||
| E | E,P | W | E,W | E,P,W | E,P,FW | E,FW | |||||
| MarioTsaBerlin Run 4 | MarioTsaBerlin_04_EolAndWeb_Avr_All_v4 | 0,92 | X | 0,885 | 0,962 | ||||||
| MarioTsaBerlin Run 2 | MarioTsaBerlin_02_EolAndWeb_Avr_6x5 | 0,915 | X | 0,877 | 0,96 | ||||||
| MarioTsaBerlin Run 3 | MarioTsaBerlin_03_EolAndFilteredWeb_Avr_3x5_v4 | 0,894 | X | 0,857 | 0,94 | ||||||
| KDETUT Run 4 | bluefield.average. | 0,853 | X | 0,793 | 0,927 | ||||||
| MarioTsaBerlin Run1 | MarioTsaBerlin_01_Eol_Avr_3x5_v2 | 0,847 | X | 0,794 | 0,911 | ||||||
| CMP Run 1 | CMP_run1_combination | 0,843 | X | 0,786 | 0,913 | ||||||
| KDETUT Run 3 | bluefield.mixed | 0,837 | X | 0,769 | 0,922 | ||||||
| KDETUT Run 2 | bluefield.noisy | 0,824 | X | 0,754 | 0,911 | ||||||
| CMP Run 3 | CMP_run3_eol | 0,807 | X | 0,741 | 0,887 | ||||||
| FHDO_BCSG Run 2 | FHDO_BCSG_2_finetuned_inception-resnet-v2_top-5-subset-web_eol | 0,806 | X | 0,738 | 0,893 | ||||||
| FHDO_BCSG Run 3 | FHDO_BCSG_3_ensemble_1_2 | 0,804 | X | 0,736 | 0,891 | ||||||
| UM Run 2 | UM_WEB_ave_run2 | 0,799 | X | 0,726 | 0,888 | ||||||
| UM Run 3 | UM_COM_ave_run3 | 0,798 | X | 0,727 | 0,886 | ||||||
| FHDO_BCSG Run 1 | FHDO_BCSG_1_finetuned_inception-resnet-v2 | 0,792 | X | 0,723 | 0,878 | ||||||
| UM Run 4 | UM_COM_max_run4 | 0,789 | X | 0,715 | 0,882 | ||||||
| KDETUT Run 1 | bluefield.trusted | 0,772 | X | 0,707 | 0,85 | ||||||
| CMP Run 2 | CMP_run2_combination_prior | 0,765 | X | 0,68 | 0,87 | ||||||
| CMP Run 4 | CMP_run4_eol_prior | 0,733 | X | 0,641 | 0,849 | ||||||
| UM Run 1 | UM_EOL_ave_run1 | 0,7 | X | 0,621 | 0,795 | ||||||
| SabanciUGebzeTU Run 4 | Sabanci-GebzeTU_Run4 | 0,638 | X | 0,557 | 0,738 | ||||||
| SabanciUGebzeTU Run 1 | Sabanci-GebzeTU_Run1 | 0,636 | X | 0,556 | 0,737 | ||||||
| SabanciUGebzeTU Run 3 | Sabanci-GebzeTU_Run3 | 0,622 | X | 0,537 | 0,728 | ||||||
| PlantNet Run 1 | PlantNet_PlantCLEF2017_runTrusted-repaired | 0,613 | X | 0,513 | 0,734 | ||||||
| SabanciUGebzeTU Run 2 | Sabanci-GebzeTU_Run2_EOLonly | 0,581 | X | 0,508 | 0,68 | ||||||
| UPB HES SO Run 3 | UPB-HES-SO_PlantCLEF2017_run3 | 0,361 | X | 0,293 | 0,442 | ||||||
| UPB HES SO Run 4 | UPB-HES-SO_PlantCLEF2017_run4 | 0,361 | X | 0,293 | 0,442 | ||||||
| UPB HES SO Run 1 | UPB-HES-SO_PlantCLEF2017_run1 | 0,326 | X | 0,26 | 0,406 | ||||||
| UPB HES SO Run 2 | UPB-HES-SO_PlantCLEF2017_run2 | 0,305 | X | 0,239 | 0,383 | ||||||
| FHDO_BCSG Run 4 | FHDO_BCSG_4_finetuned_inception-v4 | 0 | X | 0 | 0 |
| Attachment | Size |
|---|---|
| 157.68 KB | |
| 176.15 KB |
{kind=link}
{kind=link}