- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
BirdCLEF 2017

Usage scenario
The general public as well as professionals like park rangers, ecology consultants and of course ornithologists might be users of an automated bird identifying system, in the context of wider initiatives related to ecological surveillance, biodiversity conservation or taxonomy. Using audio records rather than pictures is justifiable since bird calls and songs have proven to be easier to collect and to discriminate better between species.
The 2017 bird identification task will share similar objectives and scenarios with the previous editions:
- the identification of a particular bird specimen in a recording of it,
- and the recognition of all specimens singing in raw soundscapes that can contain up to several tens of birds singing simultaneously.
The first scenario is aimed at developing new interactive identification tools, to help user and expert who is today equipped with a directional microphone and spend too much time observing and listening the birds to assess their population on the field. The soundscapes, on the other side, correspond to a much more passive monitoring scenario in which any multi-directional audio recording device could be used without or with very light user’s involvement. These (possibly crowdsourced) passive acoustic monitoring scenarios could scale the amount of collected biodiversity records by several orders of magnitude.
The organization of this task is supported by the Xeno-Canto foundation for nature sounds as well as the French projects Floris'Tic(INRIA, CIRAD, Tela Botanica) and SABIOD and EADM MaDICS
![]()
![]()
![]()
![]()
Data Collection
As the soundscapes appeared to be very challenging in 2015 and 2016 (with an accuracy below 15%), we introduce this year new soundscape recordings containing time-coded bird species annotations.
For this purpose, H. Glotin recorded in summer 2016 birds soundscapes with the support of Amazon Explorama Lodges within the BRILA-SABIOD project. These recordings have been realized into the jungle canopy at 35 meters high (the highest point of the area), and at the level of the Amazon river, in Peruvian bassin (near 3°20'42" S, 72°43'22" W). Several hours were recorded few hours during mornings and evenings at the maximum of the bird acoustic activities. The recordings are sampled at 96 kHz, 24 bits PCM, stereo, dual -12 dB, using multiple systems: TASCAM DR, SONY PMC10, Zoom H1. These valuable data have then been annotated on the field (3 days of effort) by international experts. A total of 50 species are present in these recordings. They are labeled in time and frequency, and by sex.
The training data, on the other side, is still built from the outstanding Xeno-canto collaborative database, which is the largest one in the world with hundreds of thousands of bird recordings associated to various metadata such as the type of sound (call, song, alarm, flight, etc.), the date, the locality, textual comments of the authors, multilingual common names and collaborative quality ratings. The 2017 dataset will be an enriched version of the 2016 one thanks to the new contributions of the network and a geographic extension. Basically, the new training dataset will increase the total number of species of 1500 over 36,496 audio recordings in the union of Brazil, Colombia, Venezuela, Guyana, Suriname, French Guiana, Bolivia, Ecuador and Peru.
Task overview
The goal of the task is to identify all audible birds within the test recordings. For the first scenario, the goal will be to recognize the species without any concern on temporality, but for the soundscapes, participants will be asked to provide time intervals of recognized singing birds. Each soundscape will have to be divided into segments of 5 seconds, and then the run file has to contain as much lines as the total number of predictions, with at least one prediction and a maximum of 100 predictions per test segment. Each prediction item (i.e. each line of the file) has to respect the following format:
< MediaId;TC1-TC2;ClassId;probability>
where probability is a real value in [0;1] decreasing with the confidence in the prediction, and where TC1-TC2 is an timecode interval with the format of hh:mm:ss with an length of 5 seconds (ex: 00:00:00-00:00:05, then 00:00:05-00:00:10). In the first scenario not using soundscapes the time code will be not read and participants can let empty time code.
Here is a short fake run example respecting this format on only 3 test MediaId, where the 13990 and 6871 are traditional audio records and where the MediaId 10991 is a soundscape divided into several detailed responses of each successive segment of 5 seconds:
myTeam_run2.txt
Each participating group is allowed to submit up to 4 runs built from different methods. Semi-supervised, interactive or crowdsourced approaches are allowed but will be compared independently from fully automatic methods. Any human assistance in the processing of the test queries has therefore to be signaled in the submitted runs.
Participants will be allowed to use any of the provided metadata complementary to the audio content (.wav 44.1, 48 kHz or 96 kHz sampling rate), and will also be allowed to use any external training data but at the condition that (i) the experiment is entirely re-producible, i.e. that the used external resource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such resources, (iii) the additional resource does not contain any of the test observations. It is in particular strictly forbidden to crawl training data from:
www.xeno-canto.org
For each submitted run, please give in the submission system a description of the run. A combobox will specify whether the run was performed fully automatically or with a human assistance in the processing of the queries. Then, a text area should contain a short description of the used method, for helping differentiating the different runs submitted by the same group. Optionally, you can add one or several bibtex reference(s) to publication(s) describing the method more in details. Participants have to indicate if they used a method based on
- only AUDIO
- only METADATA
- both AUDIO x METADA
The use of external training data or not also has to be mentioned for each run with a clear reference to the used data.
Metric
In the first scenario, the used metric will be the Mean Average Precision (MAP), considering each audio file of the test set as a query and computed as:
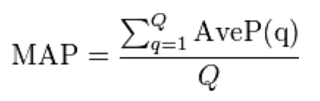
where Q is the number of test audio files and AveP(q) for a given test file q is computed as:
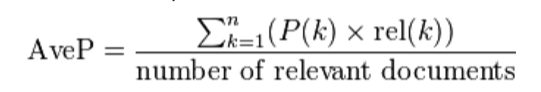
where k is the rank in the sequence of returned species, n is the total number of returned species, P(k) is the precision at cut-off k in the list and rel(k) is an indicator function equaling 1 if the item at rank k is a relevant species (i.e. one of the species in the ground truth).
In the second scenario, each test soundscape will be divided into segments of 5 seconds, and then the used metric will be also the Mean Average Precision considering each segment as a query q. Q is the above equation will be basically here the total number of segments.
Results
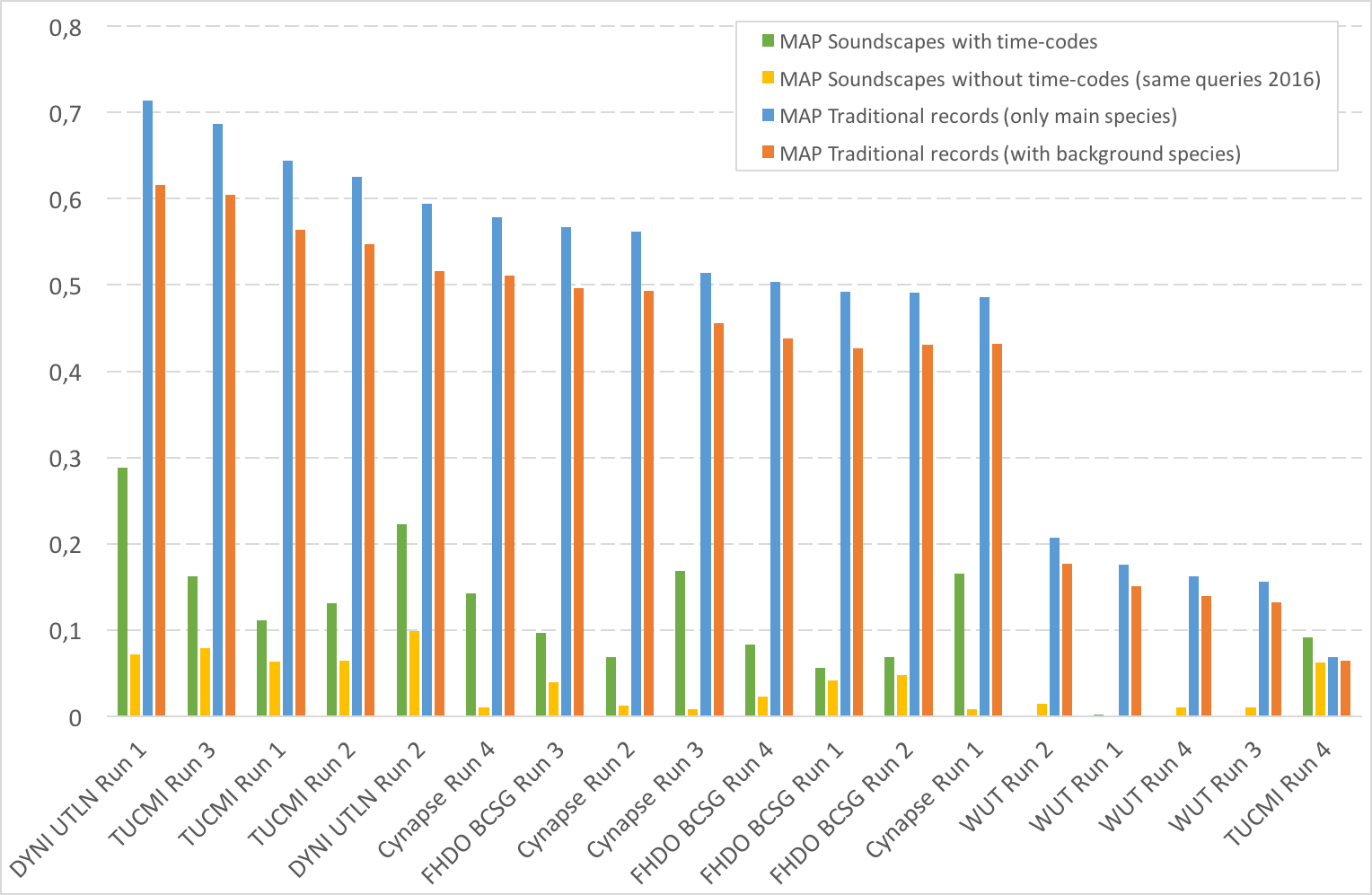
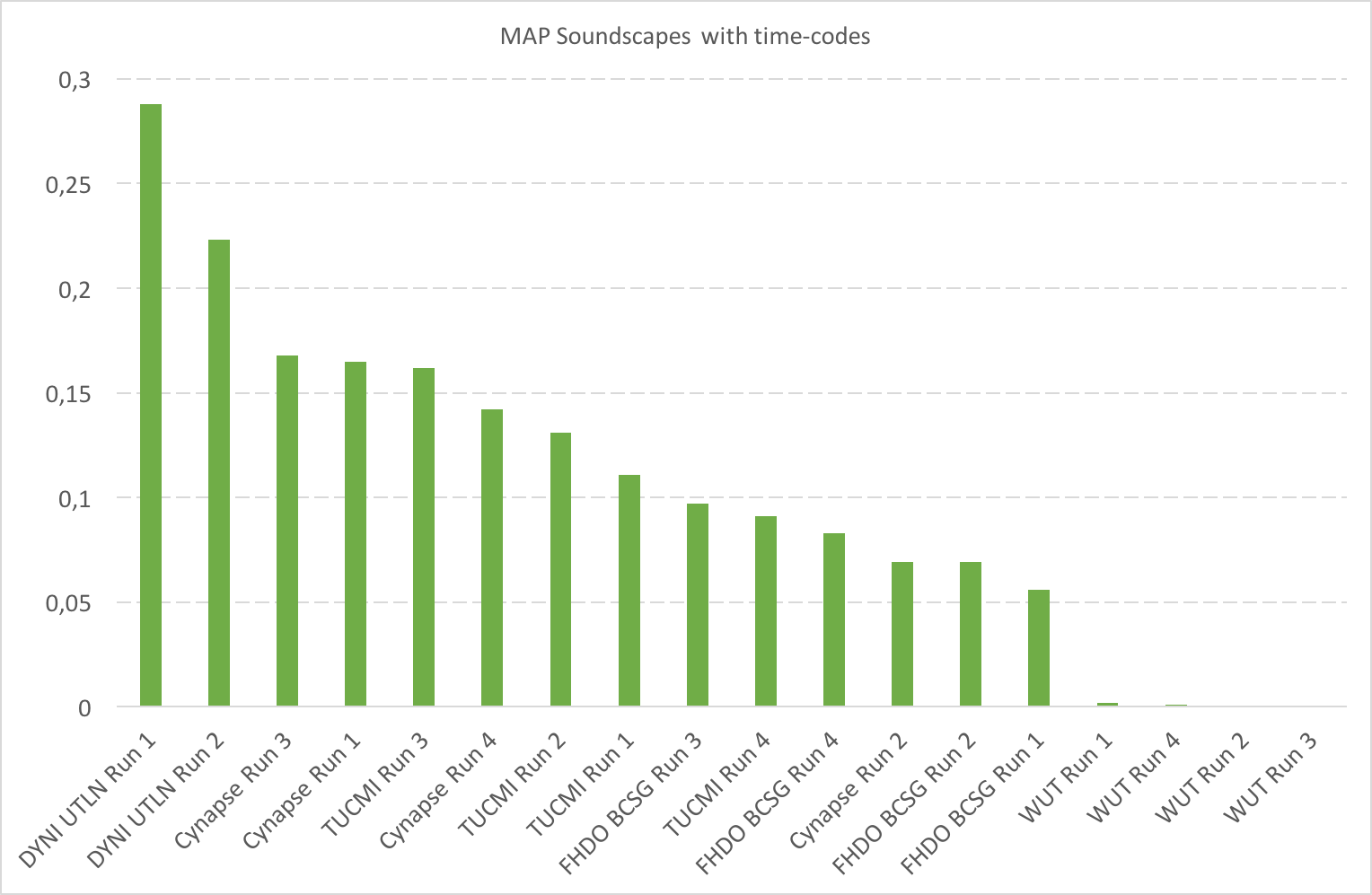
A total of 5 participating groups submitted 18 runs. Thanks to all of you for your efforts and your constructive feedbacks regarding the organization!
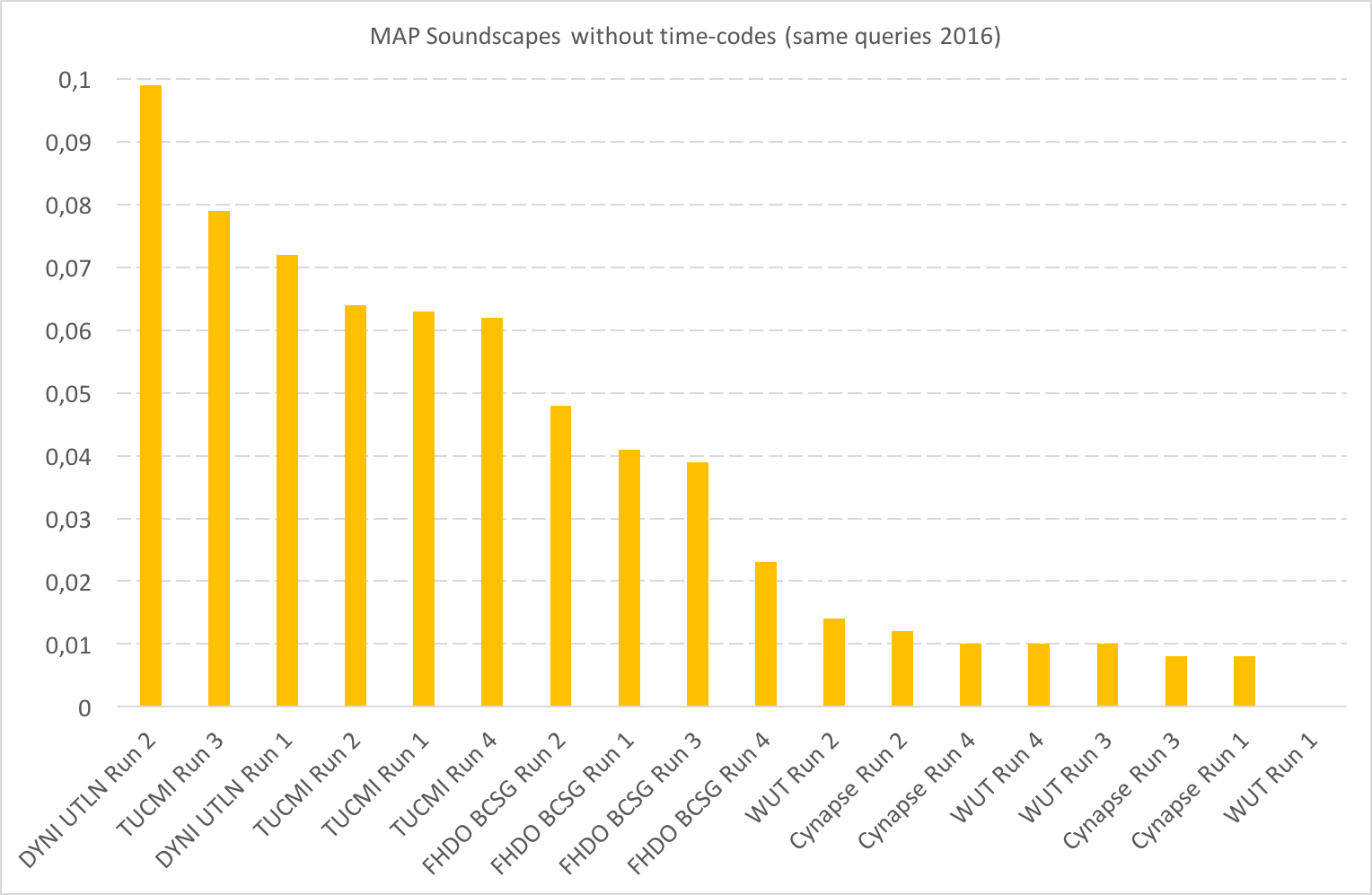
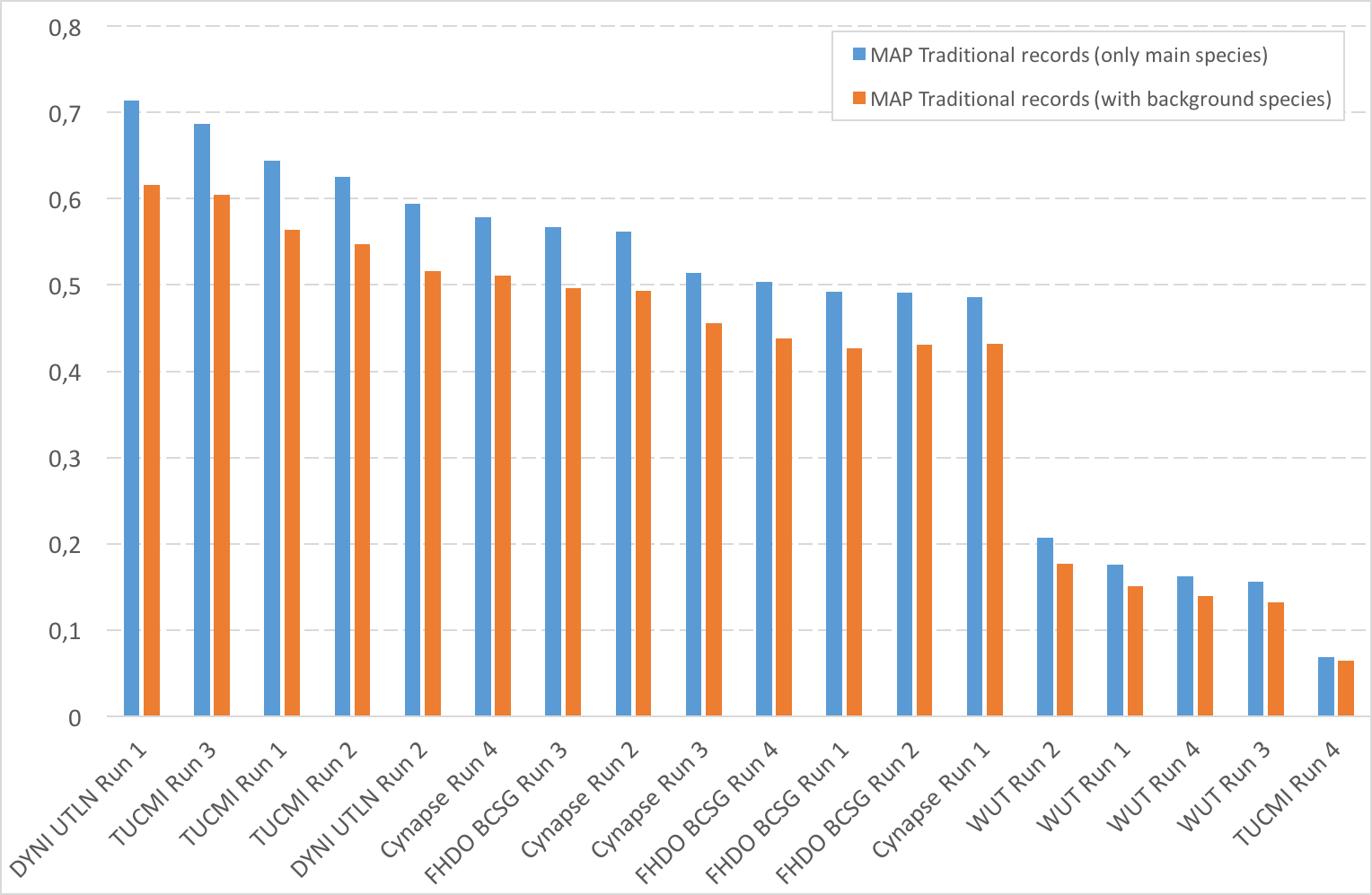
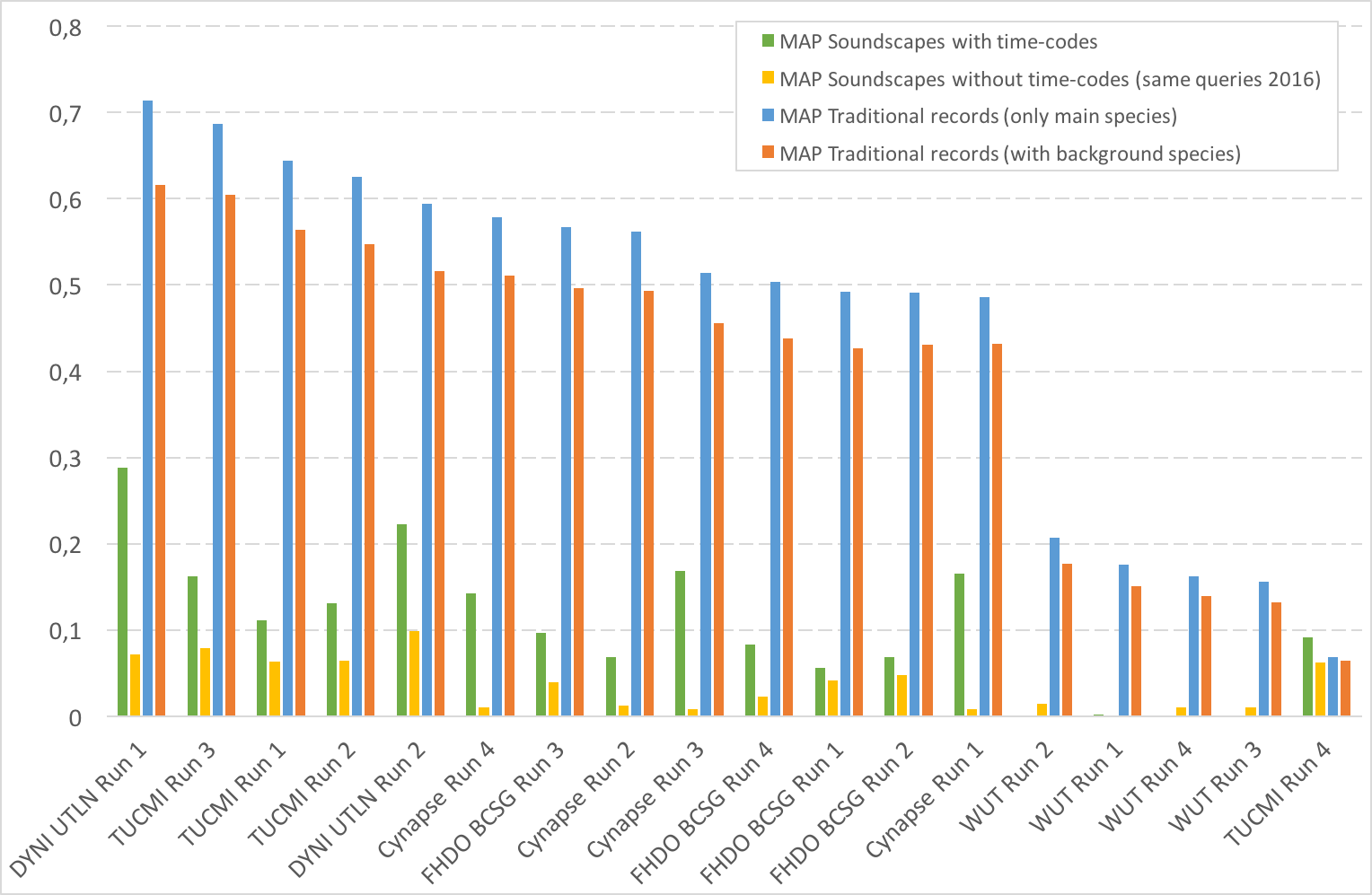
| Team (and paper) | MAP Soundscapes | MAP Soundscapes | MAP Traditional records | MAP Traditional records |
|---|---|---|---|---|
| with time-codes | without time-codes (same queries 2016) | (only main species) | (with background species) | |
| DYNI UTLN Run 1 PDF | 0,288 | 0,072 | 0,714 | 0,616 |
| DYNI UTLN Run 2 PDF | 0,223 | 0,099 | 0,594 | 0,516 |
| Cynapse Run 3 PDF | 0,168 | 0,008 | 0,514 | 0,456 |
| Cynapse Run 1 PDF | 0,165 | 0,008 | 0,486 | 0,432 |
| TUCMI Run 3 PDF | 0,162 | 0,079 | 0,687 | 0,605 |
| Cynapse Run 4 PDF | 0,142 | 0,01 | 0,579 | 0,511 |
| TUCMI Run 2 PDF | 0,131 | 0,064 | 0,625 | 0,547 |
| TUCMI Run 1 PDF | 0,111 | 0,063 | 0,644 | 0,564 |
| FHDO BCSG Run 3 PDF | 0,097 | 0,039 | 0,567 | 0,496 |
| TUCMI Run 4 PDF | 0,091 | 0,062 | 0,068 | 0,064 |
| FHDO BCSG Run 4 PDF | 0,083 | 0,023 | 0,504 | 0,438 |
| Cynapse Run 2 PDF | 0,069 | 0,012 | 0,562 | 0,493 |
| FHDO BCSG Run 2 PDF | 0,069 | 0,048 | 0,491 | 0,431 |
| FHDO BCSG Run 1 PDF | 0,056 | 0,041 | 0,492 | 0,427 |
| WUT Run 1 | 0,002 | 0 | 0,176 | 0,151 |
| WUT Run 4 | 0,001 | 0,01 | 0,162 | 0,139 |
| WUT Run 2 | 0 | 0,014 | 0,207 | 0,177 |
| WUT Run 3 | 0 | 0,01 | 0,156 | 0,132 |
| Attachment | Size |
|---|---|
| 130.82 KB | |
| 107.81 KB | |
| 116.19 KB | |
| 118.19 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}