- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
GeoLifeCLEF (pilot)

Usage scenario
Automatically predicting the list of species that are the most likely to be observed at a given location is useful for many scenarios in biodiversity informatics. First of all, it could improve species identification processes and tools by reducing the list of candidate species that are observable at a given location (be they automated, semi-automated or based on classical field guides or flora). More generally, it could facilitate biodiversity inventories through the development of location-based recommendation services (typically on mobile phones) as well as the involvement of non-expert nature observers. Last but not least, it might serve educational purposes thanks to biodiversity discovery applications providing functionalities such as contextualized educational pathways.
Data
Main and small subtasks: For this pilot edition of GeoLifeCLEF, the task has been split in two subtasks. The main subtask corresponds to the full dataset, which has been prepared according to the procedure detailed in the following paragraphs. In parallel, the "small" subtask works on the same principle, but is based on a restriction of the data (sub-selection of a 100 species and associated observations). The "small" dataset is meant to give easier access to the task to people lacking time or calculation resources for the main dataset.
Species list: We focus on West Europe plant species. The main list is constituted of 855 plant species selected according to the following constraints :
1. The species belong to the set of observations produced by the Pl@ntNet platform in 2016, geolocated in metropolitan
France and for which the identification has been confirmed by at least one person.
2. The species name matches the world scale checklist of accepted names called "The Plant List" (http://www.theplantlist.org/)
3. The species name matches the GBIF backbone taxonomy (http://www.gbif.org/dataset/d7dddbf4-2cf0-4f39-9b2a-bb099caae36c)
The small list is a sub-selection of 100 species.
Test set: The test set is composed of 4058 occurrences of plant species belonging to the targeted list of 855 species. All these observations were collected in 2016 and validated in the context of the Pl@ntNet initiative [1,2]. The geo-coordinates of each occurrence will be provided but the species name will be occulted so as to be used for evaluating the list of species recommended by the evaluated systems (based on the mean reciprocal rank, see the metric section). The small test set is an extraction of 1342 occurrences with species of the small list.
Training set: The Global Biodiversity Information Facility (GBIF) is the world’s largest open data infrastructure in this domain, funded by governments. It allows anyone, anywhere to access occurrence data about all types of life on Earth, shared across national boundaries via the Internet. Each record is typically composed of a geo-coordinate and a species name (and optionally a date, an observer name, etc.) in Darwin Core standard format. GBIF data can be easily accessed through the public Occurrence API in particular through the /occurrence/search web service which allows location-based occurrence retrieval or the /occurrence/download/ service which allows downloading a batch of data covering an entire area. For GeoLifeCLEF, we propose a training dataset extracted from the GBIF API, filtered and ready to use. It is constituted of 990,328 plant occurrences geolocated in metropolitan France, which species belong to GeoLifeClef 2017 list. We excluded occurrences with imperfect registration matching in the GBIF taxonomy, having a coordinate anomaly, and obviously the ones also in the test set. We did not exceed 1 million occurrences, despite GBIF data was richer, in order to keep the scale manageable for calculations and data exchange. We chose to favor diversity of species, by applying a limit of 1900 occurrences by species, rather than allowing all occurrences and keeping only the few most represented ones. Thus, for species exceeding this ceiling, we took 1900 occurrences randomly. The small train set is an extraction of 105,524 occurrences with species of the small list.
Environmental data: Using occurrence data solely for learning species distribution model is usually not possible because of strong sampling bias. Thus, in ecology, the prediction of the presence or absence of a given species at a given location, is usually based on environmental variables that characterize the environment encountered at that location (e.g. climatic data, topological data, occupancy data, etc.). For GeoLifeCLEF, we did normalize and pre-format environmental descriptors for each occurrence in the training and test sets based on the following open datasets:
-- Chelsea Climate data 1.1: those are raster data with worldwide coverage and 1km resolution. A mechanistical climatic model is used to make spatial predictions of monthly mean-max-min temperatures, mean precipitations and 19 bioclimatic variables, which are downscaled with statistical models
integrating historical measures of meteorologic stations from 1979 to today. The exact method is explained in the reference paper Karger et al. [3]. The data is under Creative Commons Attribution 4.0 International License and downloadable at (http://chelsa-climate.org/downloads/).
-- The ESDB v2 - 1kmx1km Raster Library (Panagos [4],Van Liedekerke et al. [5]): The library contains multiple soil pedology descriptor raster layers covering Eurasia at a resolution of 1km. We selected 11 descriptors from the library. More precisely, those variables have ordinal format, representing physico-chemical properties of the soil, and come from the PTRDB. The PTRDB variables have been directly derived from the initial Soil Geographical Data Base of Europe (SGDBE) using expert rules. SGDBE was a spatial semantic data base relating spatial units to a diverse pedological attributes of categorical nature, which is not useful for our purpose. For more details, see Panagos et al. [6]. The data is maintained and distributed freely for scientific use by the European Soil Data Centre (ESDAC) at http://eusoils.jrc.ec.europa.eu/content/european-soil-database-v2-raster....
-- Corine Land Cover 2012, version 18.5.1, 12/2016: It is a raster layer describing soil occupation with 48 categories across Europe (25 countries) at a resolution of 100 meters. This classification is the result of an automated interpretation process applied to earth surface high resolution satellite images. This data base of the European Union is freely accessible online for all use at http://land. copernicus.eu/pan-european/corine-land-cover/clc-2012.
-- CGIAR-CSI ETP data: The CGIAR-CSI distributes this worldwide monthly potential-evapotranspiration raster data. It is pulled from a model developed by Antonio Trabucco (see Zomer et al. [7,8]). Those are estimated by the Hargreaves formula, using mean monthly surface temperatures
and standard deviation from WorldClim 1:4 (http://www.worldclim.org/version1), and radiation on top of atmosphere. The raster is at a 1km resolution, and is freely downloadable for a nonprofit use at http://www.cgiar-csi.org/data/global-aridity-and-pet-database#description.
-- USGS Digital Elevation data: The Shuttle Radar Topography Mission achieved in 2010 by Endeavour shuttle managed to measure digital elevation at 3 arc second resolution over most of the earth surface. Raw measures have been post-processed by NASA and NGA in order to correct detection anomalies. The data is available from the U.S. Geological Survey, and downloadable on the Earthexplorer (https://earthexplorer.usgs.gov/). See https://lta.cr.usgs.gov/SRTMVF for more informations.
-- BD Carthage v3: BD Carthage is a spatial semantic database holding many informations on the structure and nature of the french metropolitan hydrological network. For the purpose of plants ecological niche, we focus on the geometric segments representing watercourses, polygons representing hydrographic fresh surfaces and seas. The data has been produced by the Institut National de l’information Géographique et forestière (IGN) from an interpretation of the BD Ortho IGN. It is maintained by the SANDRE under free license for non-profit use and downloadable at http://services.sandre.eaufrance.fr/telechargement/geo/ETH/BDCarthage/FX....
-- ROUTE500 1.1: This database register classified road linkage between cities (highways, national road and departmental roads) all over France and in shapefile format, representing around 500 000km of roads. It is produced under free license (all uses) by the IGN. Data is available online at http://osm13.openstreetmap.fr/~cquest/route500/.
Environmental descriptors
We detail in the following table the environmental variables provided for each occurrence in the training and test sets (based on the environmental data described above).
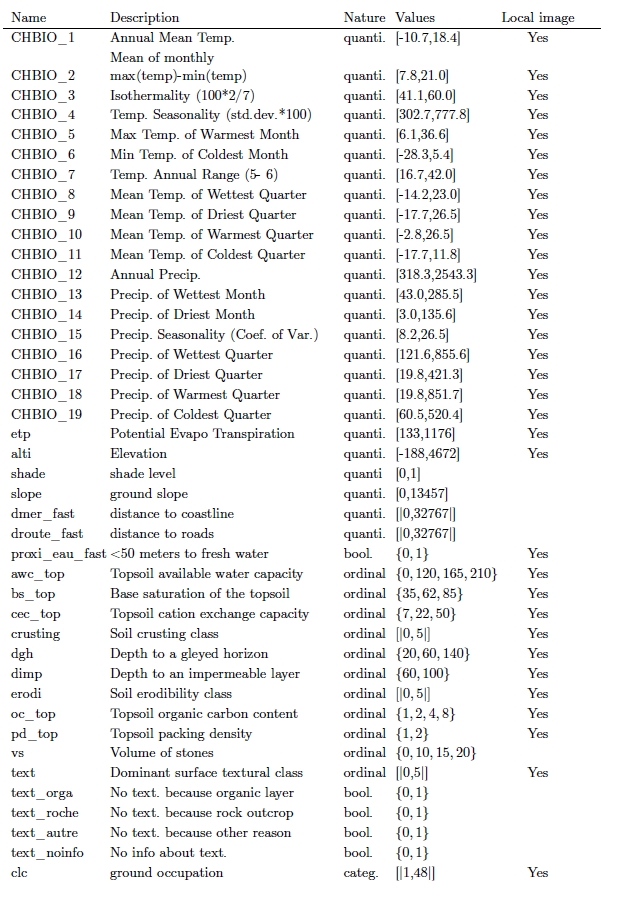
For reproducibility, we explain the treatments applied to the original data. As a first treatment, we crop the source layers as short as possible to make calculations faster, making sure the extent contains all the metropolitan France territory. Then, as the original coordinate system of
the layer vary among sources, we change it to WGS84, which is the occurrences coordinate system of the Pl@ntNet and GBIF occurrences data bases. Additional processing were necessary to get proximity and distance variables. Thus, some raster variables (i.e. proxi_eau, dmer and droute) have been made from vector shapefiles according to the following procedure. For proxi_eau, i.e. the proximity to fresh water, we use qgis to rasterize to a 12.5 meters resolution, with a buffer of 50 meters, the shapefile COURS_D_EAU.shp on one hand, and the polygons of SURFACES_HYDROGRAPHIQUES.shp with attribute NATURE="Eau douce permanente" on the other hand. We then create the maximum raster of the previous ones (So the value of 1 correspond to an approximate distance of less than 50 meters to a watercourse or hydrographic surface of fresh water). For dmer, i.e. the distance to sea, we calculated, using Qgis, the distance raster at a resolution of 12.5m to polygons with attribute TYPE = "Pleine mer" in the shapefile SURFACES_HYDROGRAPHIQUES.shp of BD Carthage up to a distance of 32,767 meters for storage format convenience. For droute, i.e. the distance to the main roads networks, we used a similar procedure as for dmer, calculating distance raster for all the elements of the shapefile ROUTES.shp (segments).
For convenience of participants in this new task, we provide occurrences linked with associated environnemental variables under two formats described here.
-- Environmental feature vectors: We provide two data tables occ_train.csv and occ_test.csv containing respectively the training and test occurrences. Inside, one can find that each line correspond to a single occurrence. The columns are composed of the occurrence identifier glc_id, Latitude, Longitude indicating the geolocation in WGS84 coordinate system, identifier of source dataset, organism, the year, coordinate uncertainty in meters (for train set), and then a column for each environmental variable which value is found in the cell containing the point in the raster (see previous section), and two more columns for the train dataset, species indicating the scientific name of the species in "The Plant List" taxonomy, and taxonkey which is the species identifier.
-- Environmental local image patches: Local values taken by an environmental variable around an occurrence may be seen as an image useful to characterize the ecological niche of a species. In this context, we provide two uncompressed archive files occ_pic_train.tar and occ_pic_test.tar. In each, one can find in the main directory a directory per occurrence. Inside the directory occ_xxx, where xxx is the occ_id of the occurrence, can be found, for each environmental
variable, a TIFF raster file of size 64x64 (pixels). 33 variables are provided in this format (see table), which are the 19 bioclimatic variables, etp, alti, 10 pedologic variables, proxi_eau_fast and clc. For a given variable, let’s denote resx the resolution in longitude of its raster global raster, resy the resolution in latitude, lo the occurrence’s longitude and la its latitude. The picture raster is made with the cells of the global raster containing the square delimited lo-resx*32 as minimal longitude, lo+resx*32 as maximal, la-resy*32 as minimal latitude and la+resy *32 as maximal. Values stored in each pixel of a TIFF file are beetween 0 and 255. For "awc_top", "bs_top", "cec_top", "crusting", "dgh", "dimp", "erodi", "oc_top", "pd_top", "text", "clc", and "proxi_eau_fast" there is no transformation, so the pixel value corresponds exactly to the original one. However, for "chbio_xx","alti" and "etp" one will recover the original value by applying the following operation :
original_value = min + (max-min) [ (pixel_value/255) -0.1 ] /0.8
max and min corresponds to the maximum and minimum values taken by the variable, they are indicated in the table above. For variables where 0 doesn't belong to the ensemble of values precised in the table above, a pixel value of 0 means there is no information available at that location.
External data
Participants are allowed to use other external training data but at the condition that (i) the experiment is entirely re-produceable, i.e. that the used external ressource is clearly referenced and accessible to any other research group in the world, (ii) participants submit at least one run without external training data so that we can study the contribution of such ressources, (iii) the additional ressource does not contain any of the test observations.
Task description
Data for main subtask can be downloaded at http://otmedia.lirmm.fr/LifeCLEF/GeoLifeCLEF2017/main/, while small subtask is at http://otmedia.lirmm.fr/LifeCLEF/GeoLifeCLEF2017/short/. Each participant have the choice to do just one of the subtasks or both by submitting separated runs (abbreviation "GLC" or "GLCsmall" has to be in a run file name to identify the subtask) as if they were separated tasks.
Given the test set of XX spatial occurrences of plants, the goal of the task is to return for each occurrence a ranked list of plant species sorted according to the likelihood that they might have been observed at that location. The test set as well as the list of the XX candidate species will be provided within the registration/submission system (see main page of LifeCLEF 2017 for registration).
Each participating group is allowed to submit up to 4 run files built from different methods. Each run file has to be named as "teamname_runX.run" where X is the identifier of the run (i.e. 1, 2, 3 or 4). The run file has to contain as much lines as the total number of species recommendations, with at least one recommendation per occurrence of the test set and a maximum of XX recommendations per occurrence (1 000 being the total number of species). Each recommendation (i.e. each line of the run file) has to respect the following format:
< occ_id;species_id;probability;rank>
where occ_id is the identifier of an occurrence in the test set, species_id is the identifier of one of the 860 possible species, probability is a real value in [0;1] decreasing with the confidence in that recommendation, rank is the rank of that recommendation among all recommended species for the test occurrence occ_id.
Here is a short fake run example respecting this format on only 3 test occurrences:
GLC_myTeam_run2.txt
For each submitted run, please give within the submission system a short description of the run in the dedicated text area (in addition to the working note to be written later on).
Metric
The used metric will be the Mean Reciprocal Rank (MRR). The MRR is a statistic measure for evaluating any process that produces a list of possible responses to a sample of queries (spatial occurrences in our case), ordered by probability of correctness. The reciprocal rank of a query response is the multiplicative inverse of the rank of the first correct answer. The MRR is the average of the reciprocal ranks for the whole test set:
where |Q| is the total number of query occurrences in the test set.

References
[1] Joly, A., Goëau, H., Champ, J., Dufour-Kowalski, S., Müller, H., & Bonnet, P. (2016, October). Crowdsourcing Biodiversity Monitoring: How Sharing your Photo Stream can Sustain our Planet. In Proceedings of the 2016 ACM on Multimedia Conference (pp. 958-967). ACM.
[2] Joly, A., Bonnet, P., Goëau, H., Barbe, J., Selmi, S., Champ, J., ... & Boujemaa, N. (2015). A look inside the Pl@ntNet experience. Multimedia Systems, 1-16.
[3] Karger, Dirk Nikolaus, Conrad, Olaf, Böhner, Jürgen, Kawohl, Tobias, Kreft, Holger, Soria-Auza,
Rodrigo Wilber, Zimmermann, Niklaus, Linder, H Peter, & Kessler, Michael. 2016. Climatologies
at high resolution for the earth’s land surface areas. arXiv preprint arXiv :1607.00217.
[4] Panagos, Panos. 2006. The European soil database. GEO : connexion, 5(7), 32–33.
[5] Panagos, Panos, Van Liedekerke, Marc, Jones, Arwyn, & Montanarella, Luca. 2012. European Soil
Data Centre : Response to European policy support and public data requirements. Land Use Policy,
29(2), 329–338.
[6] Van Liedekerke, M, Jones, A, & Panagos, P. 2006. ESDBv2 Raster Library-a set of rasters derived
from the European Soil Database distribution v2. 0. European Commission and the European Soil
Bureau Network, CDROM, EUR, 19945.
[7] Zomer, Robert J, Bossio, Deborah A, Trabucco, Antonio, Yuanjie, Li, Gupta, Diwan C, & Singh,
Virendra P. 2007. Trees and water : smallholder agroforestry on irrigated lands in Northern India.
Vol. 122. IWMI.
[8] Zomer, Robert J, Trabucco, Antonio, Bossio, Deborah A, & Verchot, Louis V. 2008. Climate change
mitigation : A spatial analysis of global land suitability for clean development mechanism afforestation
and reforestation. Agriculture, ecosystems & environment, 126(1), 67–80.
| Attachment | Size |
|---|---|
| 437.15 KB | |
| 11.11 KB |
{kind=link}