- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Handwritten Scanned Document Retrieval Task 2016
Welcome to the website of the ImageCLEF 2016 Handwritten Scanned Document Retrieval Task!
News
-
The task overview paper is now available at ceur-ws.org/Vol-1609/16090233.pdf.
- The overview presentation slides are available here.
- The dataset is available at doi:10.5281/zenodo.52994.
Schedule
- 15.11.2015: registration opens (registration instructions)
- 16.12.2015: release of development data
- 25.02.2016: release of evaluation script and baseline system (baseline results)
- 17.03.2016: release of test data (dataset description)
- 01.04.2016: release of test set query list
0107.05.2016: deadline for submission by the participants (instructions)- 15.05.2016: release of processed results
2528.05.2016: deadline for submission of working notes papers by the participants- 17.06.2016: notification of acceptance of the working notes papers
- 01.07.2016: camera ready working notes papers
- 05.-08.09.2016: CLEF 2016, Évora, Portugal
Overview
Motivation
In recent years there has been an increasing interest in digitizing the vast amounts of pre-digital age books and documents that exist throughout the world. Many of the emerging digitizing initiatives are aimed at dealing with huge collections of handwritten documents, for which automatic recognition is not yet as mature as for printed text Optical Character Recognition (OCR). Thus, there is a need to develop reliable and scalable indexing techniques for manuscripts, targeting its particular challenges. Users for this technology could be libraries with fragile historical books, which for preservation are being scanned to make them available to the public without the risk of further deterioration. Apart from making the scanned pages available, there is also interest in providing search facilities so that the people consulting these collections have information access tools that they are already accustomed to have. The archaic approach is to manually transcribe and then use standard text retrieval. However, this becomes too expensive for large collections. Alternatively, handwritten text recognition (HTR) techniques can be used for automatic indexing, which requires to transcribe only a small part of the document for learning the models, or reuse models obtained from similar manuscripts, thus requiring the least human effort.
Targeted participants
This task tries to allow easy participation from different research communities (by providing prepared data for each), with the aim of having synergies between these communities, and providing different ideas and solutions to the problems being addressed. In particular, we hope to have participation at least from groups working on: handwritten text recognition, keyword spotting and (digital) text retrieval.
Task description
The task is aimed at evaluating the performance of indexing and retrieval systems for scanned handwritten documents. Specifically, the task targets the scenario of free text search in a document, in which the user wants to find sections of the document for a given multiple word textual query. The result of the search is not pages, but smaller regions (such as a paragraph), which could even include the end of a page and start of the next. The system should also be able to handle broken words due to hyphenation and words that were not seen in the data used for learning the recognition models.

Figure 1. Example of a search result in a handwritten document.
Since the detection of paragraphs is in itself a difficult problem, to simplify things the definition of the segments to retrieve will be simply a concatenation of 6 consecutive lines (from top to bottom and left to right if there are columns), ignoring the type of line it may be (e.g. title, inserted word, etc.). More precisely, the segments are defined by a sliding window that moves one line at a time (thus neighbouring segments overlap by 5 lines) traversing all the pages in the document, so there are segments that include lines at the end of a page and at the beginning of the next, and the total number of segments is #lines_in_collection - 5.
The queries are one or more words that have to be searched for in the collection and a segment is considered relevant if all the query words appear in the given order. Due to the overlap of the segments, for a given query, several consecutive segments will be relevant. In a real application these consecutive segments would be fused into one result, however, to simplify the evaluation the submissions must include all relevant segments. The participants are expected to submit for each query only for the segments considered relevant a relevancy score and the bounding boxes of all appearances of the query words within the segment irrespectively if it is or not an instance of the word that made the segment relevant. The queries have been selected such that some key challenges are included: words broken due to end of line hyphenation, queries with words not seen in the training data, queries with a repeated word, and queries with zero relevant results. An optional track will be proximity search. More details later. The proximity search track has been left for a future edition of this handwritten retrieval evaluation.
Since the evaluation will measure the impact of words not seen in the training set, the use of external data for learning a language model is prohibited. The use of external data for learning the optical models is allowed, but with the condition that results are also submitted using the same techniques and only the provided data for learning the optical models. The development set should not be used as training since the development set is actually part of the test set.
The task will not require the detection of the text lines, they will be assumed to be already detected.
Registering for the task and accessing the data
To participate in this task, please register by following the instructions found in the main ImageCLEF 2016 web page. The data is available at www.prhlt.upv.es/contests/iclef16, although the access details will be available only after registering. The user name and password are found in the ImageCLEF system going to Collections and then Detail of the c_ic16_handwritten_retrieval collection.
Now that the evaluation is over, the dataset is freely available at doi:10.5281/zenodo.52994. Please check the overview paper for recommendations on how to use the data.
Additional to the task registration, it is recommended that you follow the @imageclef twitter account to receive the latest announcements.
Dataset description
The dataset used in this task is a subset of pages from unpublished manuscripts written by the philosopher and reformer, Jeremy Bentham, that have been digitised and transcribed under the Transcribe Bentham project [Causer 2012]. The data is divided into three sets, training (363 pages), development (433 pages) and test (the same 433 pages from development plus 200 new pages). For all the three sets the original scanned page colour images are provided, each with an XML file in Page format that includes some metadata.
The training set XMLs include the transcripts, polygons surrounding every line that have been manually checked and also word polygons that were automatically obtained (these would be used by the groups working in query-by-example keyword spotting). The development set additionally has transcripts, manually checked line and word polygons, a list of 510 queries and the respective retrieval ground truth (obtained using the word polygons). The test set will have baselines instead of the polygons surrounding the lines, and the list of queries will be different.
To ease participation, the text lines are also provided as extracted images. These lines have in their metadata the crop window offset required to compute bounding boxes in the original page image coordinates. Additionally for each line, n-best recognition lists are given (including log-likelihoods and bounding boxes), with the aim that researchers that work on related fields (such as text retrieval) but don't normally work with images or HTR can easily participate.
[Causer 2012] T. Causer and V. Wallace, Building a Volunteer Community: Results and Findings from Transcribe Bentham, Digital Humanities Quarterly, Vol. 6 (2012), http://www.digitalhumanities.org/dhq/vol/6/2/000125/000125.html
Submission instructions
Important: Note that the test set is composed of the development set pages plus 200 new pages. The final performance measures will only be computed using the new pages. Though, be sure to use exactly the same system and parameters for processing all 633 pages (16939 segments), since the techniques will also be judged by its generalization ability (i.e. a comparison will be made between the performance of the development and the 200 new test pages). As mentioned before, the development set can't be used as training.
The submissions will be received through the ImageCLEF 2016 system, going to "Runs" and then "Submit run" and select track "ImageCLEF handwritten retrieval". Apart from uploading the submission file, the only field that you need to provide is the "Method Description", all others ("Retrieval type", "Language", "Run Type", etc.) can be left with their default values since they will be ignored. A maximum of 10 submissions will be allowed per group.
Submission files will be restricted to be maximum 8MB of size. If you have a larger file, you will need to remove low confidence matches to keep the file size within the limit.
The solution files (also called runs) are in plain text, starting with a 6 line header and followed by the actual retrieval results. The header is intended to ease processing and categorization of the types of submissions and is of the form:
# group_id: GROUP # system_id: TECHNIQUE # uses_external_training: (yes|no) # uses_provided_nbest: (yes|no) # uses_provided_lines: (yes|no) # query_by_example: (yes|no)
where GROUP is the name of your team (preferably the initials of your institution or lab) and TECHNIQUE is a very short name for the particular submission, e.g. HMM-32gauss, (ideally it should be the same as how that particular result will be called in the working notes paper). The other four header lines is to specify if the system: uses or does not use external training data; if it uses or does not use the provided N-best recognition results; if it uses the provided extracted line images or the lines were extracted from the original pages using a different technique to determine the area of the image to extract; and if the technique is based on query by example. If your group plans to submit results using external training data, remember that another submission must be made for the same system and parameters but using only the provided training data. For both of these submissions, the header "system_id" would be the same and "uses_external_training" would be "yes" and "no" respectively.
After the header, the retrieval results contain several rows representing the match of a particular query in a particular image segment. Each row has 4 or more fields separated by whitespaces: the first field is an integer representing the query, the second is the integer identifier of the segment and the third field is a real number representing the relevance confidence score of the match (the higher the number, the more confident the result is). Finally, the fourth and subsequent fields represent the location(s) of each of the query words in the image segment (one field for each of the words in the query).
For each word in the query, its respective field should include the bounding boxes of all the locations where that word appears in the segment (including hyphened words). Bounding boxes are represented by a string with format: "L:WxH+X+Y", where L is the absolute line number, W and H are the width and height of the box (in pixels), and X and Y are the left-top coordinates of the box (in pixels), respectively. Finally, since we aim to include hyphened words in the retrieval results, a location can be divided in two different bounding boxes. In such case, the bounding boxes of the two word segments are separated by the slash ("/") symbol.
For instance, Figure 2 shows the six lines composing the segment number 7098 from the development set. In red, we marked the detected words for the query "building necessary" (query id 110). Observe that the segment includes one instance of the word "building" (line 7102) and two instances of the word "necessary", one of them hyphened (lines 7101 and 7102/7013, respectively). Also note that if the second instance of "necessary" did not appear, then the segment would not be relevant due to the word order restriction. An ideal retrieval system should include in its submission file a row similar to the following one:
110 7098 1.0 7102:312x135+500+3807 7101:329x131+716+3641,7102:170x45+1782+3823/7103:147x73+1822+3903

Figure 2. Result of query 110 ("building necessary") in segment 7098 from the development set.
This submission format allows to measure the performance of the system at a segment-level and word-level, display and validate the submitted results in a very easy manner, while keeping the submission files small.
Evaluation methodology
A script that computes the following evaluation measures from the ground truth and a submission file can be found in the dataset server, the file assessment.py. The assessment script requires python 2.7 and the GDAL python package (on debian-based systems simply install by: sudo apt-get install python-gdal).
The submitted solutions will be evaluated using different Information Retrieval metrics. We will compute, at least the following scores (both at a segment and word-level):
-
Global Average Precision (AP): The (Global) Average Precision measures the performance of a set of retrieval results based on the precision (p) and recall (r) metrics. The "Global" keyword refers to the fact that the precision and recall are computed taking into account the global list of results, submitted by each participant. If a submitted solution has N rows sorted by its confidence score, then the Global Average Precision is computed using the following formula:
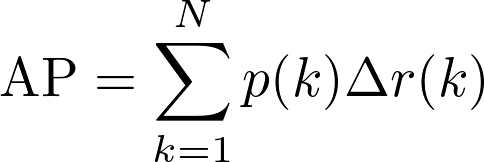
-
Mean Average Precision (mAP): This metric differs from the Global Average Precision by the fact that first computes the Average Precision for each individual query (i.e. precision and recall only consider results from each particular query), and then computes the mean among all queries.
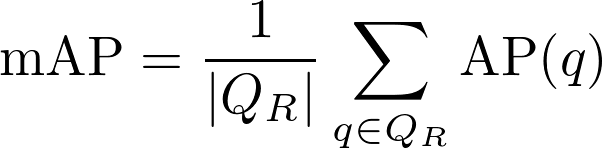
Since precision and recall are only defined when at least there is one relevant segment, and some of the queries that we have included do not have any relevant segment associated, the mAP will only be computed taking into account the set of queries that have at least one relevant segment (QR). Realize that the Global Average Precision does not present this problem as long as at least one query has at least one relevant segment, which is the case.
-
Global Normalized Discounted Cumulative Gain (NDCG): The Normalized Discounted Cumulative Gain is a widely used metric to evaluate the quality of search engines. Here, we use to keyword "Global" as we did for the Average Precision: to remark the fact that all the retrieved results are considered at once, regardless of their query. The following definition of NDCG will be used:
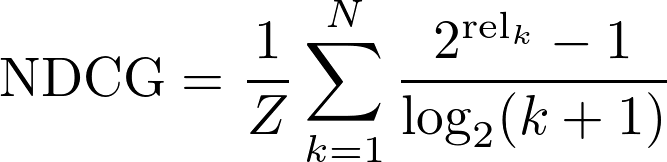
Here, relk is a binary value denoting whether the result k in the submission file is relevant or not, according to the ground truth. Z is a normalization factor (sometimes denoted as INDCG) computed from the ideal submission file, so that the NDCG is a value between 0.0 and 1.0.
-
Mean Normalized Discounted Cumulative Gain (mNDCG): Usually, this metric is referred simply as Normalized Discounted Cumulative Gain in the literature. However, we added the "Mean" keyword to denote the fact that the NDCG scores are computed individually for each query and then the average is computed among all queries, as in the distinction between Global and Mean Average Precision. The formula used to compute this metric is simply:
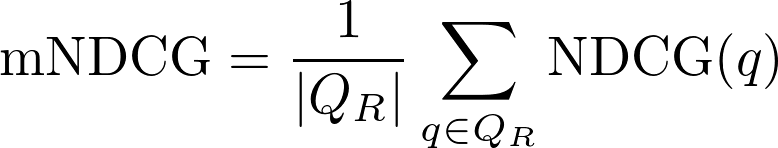
As it happened with the Average Precision, the NDCG is not well-defined when there are not relevant documents associated to a set of queries, since the normalization factor is 0.0. Thus, the mNDCG will only be computed taking into account the set of queries with at least one relevant segment associated.
In order to compute these scores at a word-level, a measure of overlapping degree between the reference and the retrieved bounding boxes needs also to be defined. The overlapping scores between two bounding boxes A and B will be computed taking into account the areas of their intersection and their union:
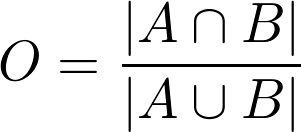
Baseline results
A very simple baseline system is being provided so that it serves as a starting point or just for initial comparisons and understanding the submission format. The baseline is based on searching for exact matches of the query words in the n-best results, thus it does not consider particular challenges such as words not seen in training or words broken due to end of line hyphenation.
Both the scripts needed for computing the retrieval results for the development set, and the actual results file generated can be found here and . The performance measures for this baseline system on the development set are:
- Segment-Level Global AP = 74.2%
- Segment-Level Mean AP = 50.0%
- Segment-Level Global NDCG = 80.1%
- Segment-Level Mean NDCG = 51.6%
- Box-Level Global AP = 53.1%
- Box-Level Mean AP = 41.3%
- Box-Level Global NDCG = 51.6%
- Box-Level Mean NDCG = 38.6%
Acknowledgements
This work has been partially supported through the EU H2020 grant READ (Recognition and Enrichment of Archival Documents) (Ref: 674943) and the EU 7th Framework Programme grant tranScriptorium (Ref: 600707). 

Organisers

![]()
- Mauricio Villegas <mauvilsa@prhlt.upv.es>
- Joan Puigcerver <joapuipe@prhlt.upv.es>
- Alejandro H. Toselli <ahector@prhlt.upv.es>
- Joan Andreu Sánchez <jandreu@prhlt.upv.es>
- Enrique Vidal <evidal@prhlt.upv.es>
| Attachment | Size |
|---|---|
| 2.93 KB |