- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
ImageCLEFdrawnUI
Motivation
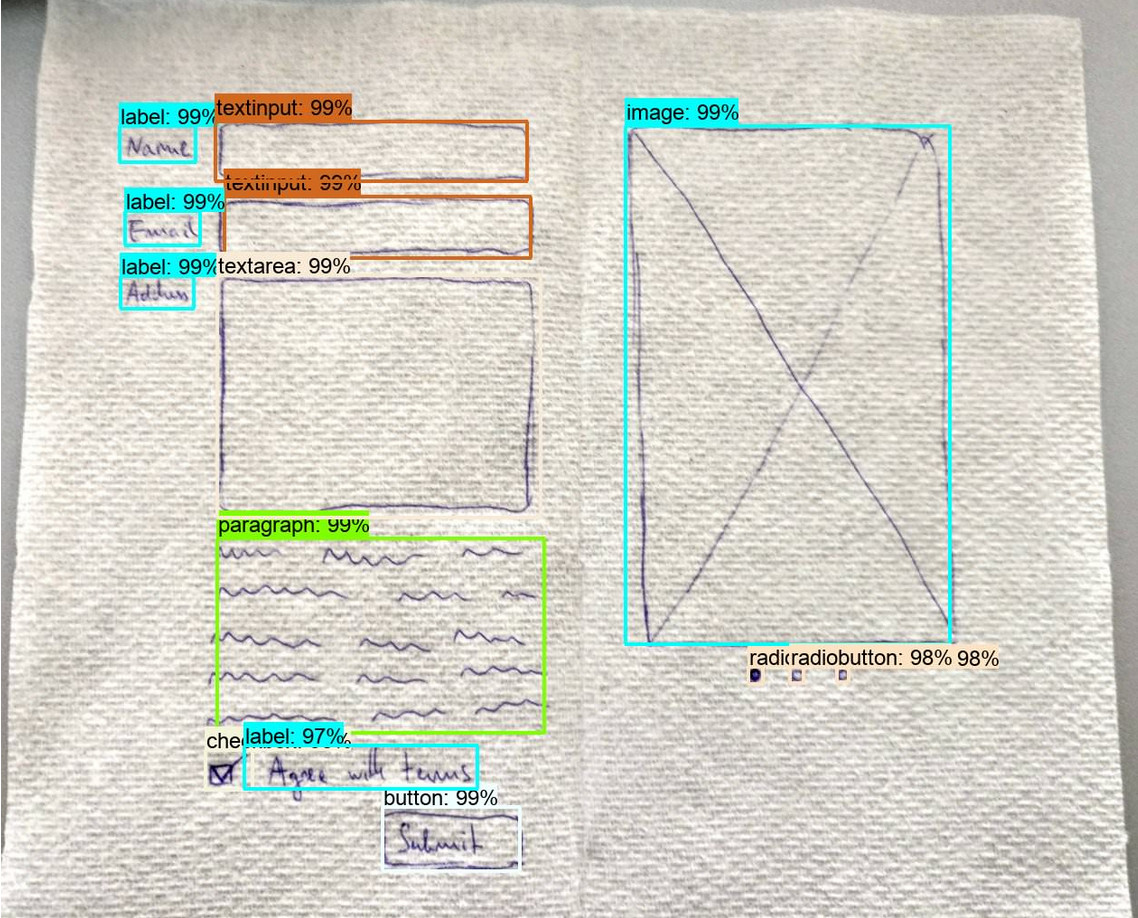
The increasing importance of User Interfaces (UIs) for companies highlights the need for novel ways of creating them. Currently, this activity can be slow and error prone due to the constant communication between the specialists involved in this field, e.g., designers and developers. The use of machine learning and automation could speed up this process and ease access to the digital space for companies who could not afford it with today’s tools. A first step to build a bridge between developers and designers is to infer the intent from a hand drawn UI (wireframe) or from a web screenshot. This is done by detecting atomic UI elements, such as images, paragraphs, containers or buttons.
In this edition, two tasks are proposed to the participants, both requiring them to detect rectangular bounding boxes corresponding to the UI elements from the images. The first task, wireframes annotation, is a continuation of the previous edition, where about 1,300 more wireframes are added to the existing 3,000 images of the previous data set. These new images will contain a bigger proportion of the rare classes to tackle the long tail problem found in the previous edition. For the second task we present the new challenge of screenshot annotation, where 9,276 screenshots of real websites were compiled into a data set by utilizing an in-house parser. Due to the nature of the web, the data set is noisy, e.g., some of the annotations correspond to invisible elements, while other elements have missing annotations. To deal with this dirty dataset, part of the images will be cleaned manually. The development set will contain 6,555 images uncleaned and 903 images cleaned and the test set will contain 1,818 clean images.
News
Preliminary Schedule
- 16.11.2020: registration opens for all ImageCLEF tasks
- 25.01.2021: development data release starts
- 15.03.2021: test data release starts
- 07.05.2021: deadline for submitting the participants runs
- 14.05.2021: release of the processed results by the task organizers
- 28.05.2021: deadline for submission of working notes papers by the participants
- 11.06.2021: notification of acceptance of the working notes papers
- 02.07.2021: camera ready working notes papers
- 21-24.09.2021: CLEF 2021, Bucharest, Romania
Task description
Given a set of images of hand drawn UIs or webpages screenshots, participants are required to develop machine learning techniques that are able to predict the exact position and type of UI elements.
Data
Wireframe Task
The provided data set consists of 4,291 hand drawn images inspired from mobile application screenshots and actual web pages. Each image comes with the manual labeling of the positions of the bounding boxes corresponding to each UI element and its type. To avoid any ambiguity, a predefined shape dictionary with 21 classes is used, e.g., paragraph, label, header. The development set contains 3,218 images while the test set contains 1,073 images.
Comparison with last year dataset:
- All images from last year develpment set are still present in this year development set
- The test contains only new images.
- Additionnal images had been selected to rebalance the classes as much as possible.
Screenshots Task
The provided data set consists of 9,630 screenshots of sections and full pages from high quality websites gathered using an in-house parser. Each image comes with the manual labeling of the positions of the bounding boxes corresponding to each UI element and its type. To avoid any ambiguity, a predefined shape dictionary with 6 classes is used, e.g., TEXT, IMAGE, BUTTON.
The development set contains 7,770 images with 6,840 noisy screenshots in the train set and 930 manually curated screenshots in the evaluation set. The test set contains 1,860 screenshots, also manually cleaned.
Evaluation methodology
The performance of the algorithms will be evaluated using the standard Mean Average Precision over IoU 0.50 and recall over IoU 0.50.
The evaluation used the pycocotools library with a maximum number of detections of 300 and 327for the wireframe and screenshot task respectively.
Participant registration
Please refer to the general ImageCLEF registration instructions
Submission instructions
The submissions will be received through the AIcrowd system.
Participants will be permitted to submit up to 10 runs. External training data is not allowed.
The Wireframe task can be found here<\a>.
The Screenshot task can be found here<\a>.
Results
Wireframe Task
| Run id | participant_name | score | score_secondary | info |
|---|---|---|---|---|
| 134548 | vyskocj | 0.900 | 0.934 | ResNeXt101: anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256], color dept = BGR; epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134829 | vyskocj | 0.900 | 0.933 | ResNeXt101 (+5 epochs with train+val): anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256], color dept = BGR, epochs = 40 + 5 with train+val; epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256], and then set = train+val, epochs = +5 |
| 134728 | vyskocj | 0.895 | 0.927 | ResNet50 (train+val, greyscale): validation data used for training, color depth = greyscale, epochs = 40; set = training + validation, epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = greyscale, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134723 | vyskocj | 0.894 | 0.928 | ResNet50 (train+val in 80 epochs): validation data used for training, epochs = 80; set = training + validation, epochs = 80, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134181 | vyskocj | 0.889 | 0.923 | ResNet50 (aspect ratios + greyscale images): anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256], color depth = greyscale; epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = greyscale, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134232 | vyskocj | 0.888 | 0.925 | ResNet50 (train+val): validation data used for training; set = training + validation, epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134180 | vyskocj | 0.882 | 0.918 | ResNet50 (aspect ratios): anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256]; epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], anchor sizes = [16, 32, 64, 128, 256] |
| 134137 | pwc | 0.836 | 0.865 | yolov5 1 45; |
| 134133 | pwc | 0.832 | 0.858 | yolo v5 05 45; |
| 134175 | vyskocj | 0.830 | 0.863 | ResNet50 (augmentations): Random Relative Resize = 0.8 +- 0.2, Cutout = [max of 4 boxes, 5 % of width/height of image]; epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image] |
| 134113 | pwc | 0.829 | 0.852 | yolov5 10 45; |
| 134099 | pwc | 0.824 | 0.844 | yolov5 20 45; |
| 134090 | pwc | 0.824 | 0.844 | yolov5 / 20-45; |
| 132583 | pwc | 0.820 | 0.840 | YOLO XL - 200 epochs with LR, ES, pretweights; |
| 132575 | pwc | 0.810 | 0.826 | Yolov5 Large - pretrained; yololarge - 200 epochs |
| 134095 | vyskocj | 0.794 | 0.832 | ResNet50 (baseline); epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), Random Relative Resize = 0.8+-0.1, Crop = 1400 |
| 134092 | vyskocj | 0.794 | 0.832 | ResNet50 (baseline); epochs = 40, learning rate = 0.0025, gamma 0.5 (in 20 and 30 epoch), Random Relative Resize = 0.8+-0.1, Crop = 1400 |
| baseline | 0.747 | 0.763 | Faster RCNN with resnet 101 backbone | |
| 132592 | pwc | 0.701 | 0.731 | YOLOv5 XL - Only heads - 100 ep; |
| 132567 | pwc | 0.649 | 0.675 | YoloV5S with pre-trained weights; Another baseline for transfer learning |
| 132552 | pwc | 0.649 | 0.675 | YoloV5 baseline; Small model baseline |
| 134702 | AIMultimediaLab | 0.216 | 0.319 | Faster RCNN with VGG16 backbone, resized to 600x, anchors ratio [1: 1, 2.5: 1, 7: 1, 12: 1]; |
Screenshots Task
| id | participant_name | score | score_secondary | info |
|---|---|---|---|---|
| 134224 | vyskocj | 0.6284675494 | 0.8295775408 | ResNet50 (train+val): validation data used for training; set = training + validation, epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512] |
| 134716 | vyskocj | 0.6207631241 | 0.8210127799 | ResNet50 (train+val in 40 epochs): validation data used for training, epochs = 40; set = training + validation, epochs = 40, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512] |
| 134215 | vyskocj | 0.6093312386 | 0.8338180933 | ResNet50 (aspect ratios): anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512]; epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512] |
| 134214 | vyskocj | 0.6021151261 | 0.8221669206 | ResNet50 (augmentations): Random Relative Resize = 0.8 +- 0.2, Cutout = [max of 4 boxes, 5 % of width/height of image]; epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image] |
| 134217 | vyskocj | 0.6014564041 | 0.8269664431 | ResNet50 (aspect ratios + greyscale images): anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512], color depth = greyscale; epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = greyscale, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512] |
| 134207 | vyskocj | 0.5935734535 | 0.8153661614 | ResNet50 (baseline); epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.1, Crop = 1400 |
| 134603 | vyskocj | 0.5901163989 | 0.807062444 | ResNeXt101: anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512], color dept = BGR; epochs = 20, learning rate = 0.0025, gamma 0.5 (in 10 and 15 epoch), color depth = BGR, Random Relative Resize = 0.8 +- 0.2, Crop = 1400, Cutout = [max of 4 boxes, 5 % of width/height of image], anchor aspect ratios = [0.1, 0.5, 1.0, 1.5], default anchor sizes = [32, 64, 128, 256, 512] |
| baseline | 0.329 | 0.408 | Faster RCNN with resnet 101 backbone |
CEUR Working Notes
- All participating teams with at least one graded submission, regardless of the score, should submit a CEUR working notes paper.
- The working notes paper should be submitted using https://easychair.org/conferences/?conf=clef2021 and select track "Multimedia Retrieval Challenge in CLEF (ImageCLEF)". Add author information, paper title/abstract, keywords, select "Task 3 - ImageCLEFdrawnUI" and upload your working notes paper as pdf.
- The working notes are prepared using the LNCS template available at: http://www.springer.de/comp/lncs/authors.html
To facilitate authors, we have prepared a LaTex template you can download at:
https://drive.google.com/drive/folders/1K5encrAZu08WYdS5lREZ94gOOEvAUJqS?usp=sharing - Official detailed instructions for the CLEF 2021 working notes can be found here: http://clef2021.clef-initiative.eu/index.php?page=Pages/instructions_for_authors.html
Citations
When referring to the ImageCLEFdrawnUI 2021 task general goals, general results, etc. please cite the following publication:
- Raul Berari, Andrei Tauteanu, Dimitri Fichou, Paul Brie, Mihai Dogariu, Liviu Daniel Ștefan, Mihai Gabriel Constantin, Bogdan Ionescu 2021. Overview of ImageCLEFdrawnUI 2021: The Detection and Recognition of Hand Drawn and Digital Website UIs Task. In CLEF2021 Working Notes (CEUR Workshop Proceedings). CEUR-WS.org <http://ceur-ws.org>, Bucharest, Romania.
-
BibTex:
@Inproceedings{ImageCLEFdrawnUI2020,-
author = {Raul Berari and Andrei Tauteanu and Dimitri Fichou and Paul Brie and Mihai Dogariu and Liviu Daniel \c{S}tefan and Mihai Gabriel Constantin and Bogdan Ionescu},
title = {Overview of {ImageCLEFdrawnUI} 2021: The Detection and Recognition of Hand Drawn and Digital Website UIs Task},
booktitle = {CLEF2021 Working Notes},
series = {{CEUR} Workshop Proceedings},
year = {2021},
volume = {},
publisher = {CEUR-WS.org $<$http://ceur-ws.org$>$},
pages = {},
month = {September 21-24},
address = {Bucharest, Romania},
}
When referring to the ImageCLEF 2021 lab general goals, general results, etc. please cite the following publication which will be published by September 2021 (also referred to as ImageCLEF general overview):
- Bogdan Ionescu, Henning Müller, Renaud Péteri, Asma Ben Abacha, Mourad Sarrouti, Dina Demner-Fushman, Sadid A. Hasan, Serge Kozlovski, Vitali Liauchuk, Yashin Dicente, Vassili Kovalev, Obioma Pelka, Alba García Seco de Herrera, Janadhip Jacutprakart, Christoph M. Friedrich, Raul Berari, Andrei Tauteanu, Dimitri Fichou, Paul Brie, Mihai Dogariu, Liviu Daniel Ştefan, Mihai Gabriel Constantin, Jon Chamberlain, Antonio Campello, Adrian Clark, Thomas A. Oliver, Hassan Moustahfid, Adrian Popescu, Jérôme Deshayes-Chossart, Overview of the ImageCLEF 2021: Multimedia Retrieval in Medical, Nature, Internet and Social Media Applications, in Experimental IR Meets Multilinguality, Multimodality, and Interaction. Proceedings of the 12th International Conference of the CLEF Association (CLEF 2021), Bucharest, Romania, Springer Lecture Notes in Computer Science LNCS, September 21-24, 2021.
-
BibTex:
@inproceedings{ImageCLEF2021,
author = {Bogdan Ionescu and Henning M\"uller and Renaud P\’{e}teri
and Asma {Ben Abacha} and Mourad Sarrouti and Dina Demner-Fushman and
Sadid A. Hasan and Serge Kozlovski and Vitali Liauchuk and Yashin
Dicente and Vassili Kovalev and Obioma Pelka and Alba Garc\’{\i}a Seco
de Herrera and Janadhip Jacutprakart and Christoph M. Friedrich and
Raul Berari and Andrei Tauteanu and Dimitri Fichou and Paul Brie and
Mihai Dogariu and Liviu Daniel \c{S}tefan and Mihai Gabriel Constantin
and Jon Chamberlain and Antonio Campello and Adrian Clark and Thomas
A. Oliver and Hassan Moustahfid and Adrian Popescu and J\’{e}r\^{o}me
Deshayes-Chossart},
title = {{Overview of the ImageCLEF 2021}: Multimedia Retrieval in
Medical, Nature, Internet and Social Media Applications},
booktitle = {Experimental IR Meets Multilinguality, Multimodality, and
Interaction},
series = {Proceedings of the 12th International Conference of the CLEF
Association (CLEF 2021)},
year = {2021},
volume = {},
publisher = {{LNCS} Lecture Notes in Computer Science, Springer},
pages = {},
month = {September 21-24},
address = {Bucharest, Romania}
}Organizers
- Dimitri Fichou <dimitri.fichou(at)teleporthq.io>, teleportHQ, Cluj Napoca, Romania
- Raul Berari <raul.berari(at)teleporthq.io>, teleportHQ, Cluj Napoca, Romania
- Andrei Tauteanu <andrei.tauteanu(at)teleporthq.io>, teleportHQ, Cluj Napoca, Romania
- Paul Brie <paul.brie(at)teleporthq.io>, teleportHQ, Cluj Napoca, Romania
- Mihai Dogariu, University Politehnica of Bucharest, Romania
- Liviu Daniel Ștefan, University Politehnica of Bucharest, Romania
- Mihai Gabriel Constantin, University Politehnica of Bucharest, Romania
- Bogdan Ionescu, University Politehnica of Bucharest, Romania
Acknowledgements
-
Mihai Dogariu, Liviu-Daniel Ștefan, Mihai Gabriel Constantin and Bogdan Ionescu's contribution to this task is supported under project AI4Media, A European Excellence Centre for Media, Society and Democracy, H2020 ICT-48-2020, grant #951911.