- ImageCLEF 2025
- LifeCLEF 2025
- ImageCLEF 2024
- LifeCLEF 2024
- ImageCLEF 2023
- LifeCLEF 2023
- ImageCLEF 2022
- LifeCLEF2022
- ImageCLEF 2021
- LifeCLEF 2021
- ImageCLEF 2020
- LifeCLEF 2020
- ImageCLEF 2019
- LifeCLEF 2019
- ImageCLEF 2018
- LifeCLEF 2018
- ImageCLEF 2017
- LifeCLEF2017
- ImageCLEF 2016
- LifeCLEF 2016
- ImageCLEF 2015
- LifeCLEF 2015
- ImageCLEF 2014
- LifeCLEF 2014
- ImageCLEF 2013
- ImageCLEF 2012
- ImageCLEF 2011
- ImageCLEF 2010
- ImageCLEF 2009
- ImageCLEF 2008
- ImageCLEF 2007
- ImageCLEF 2006
- ImageCLEF 2005
- ImageCLEF 2004
- ImageCLEF 2003
- Publications
- Old resources
You are here
Plant identification task 2011
| News |
| A direct link to the overview of the task: The CLEF 2011 Plant Images Classification Task, Hervé Goëau, Pierre Bonnet Alexis Joly, Nozha Boujemaa, Daniel Barthelemy, Jean-François Molino, Philippe Birnbaum, Elise Mouysset, and Marie Picard, CLEF 2011 working notes, Amsterdam, The Netherlands |
| Dataset: A public package containing the data of the 2011 plant retrieval task is now available (including the ground truth and an executable to compute scores). The entire data is under Creative Common license. |
Introduction
If agricultural development is to be successful and biodiversity is to be conserved, then accurate knowledge of the identity, geographic distribution and uses of plants is essential. Unfortunately, such basic information is often only partially available for professional stakeholders, teachers, scientists and citizens, and often incomplete for ecosystems that possess the highest plant diversity. So that simply identifying plant species is usually a very difficult task, even for professionals (such as farmers or wood exploiters) or for the botanists themselves. Using image retrieval technologies is nowadays considered by botanists as a promising direction in reducing this taxonomic gap. Evaluating recent advances of the IR community on this challenging task might therefore have a strong impact. The organization of this task is funded by the French project Pl@ntNet (INRIA, CIRAD, Telabotanica) and supported by the European Coordination Action CHORUS+.
Overview
This first year pilot task will be focused on tree species identification based on leaf images. Leaves are far from being the only discriminant key between tree species but they have the advantage to be easily observable and the most studied organ in the computer vision community. The task will be organized as a classification task over 70 tree species with visual content being the main available information. Additional information only includes contextual meta-data (author, date, locality name) and some EXIF data. Three types of image content will be considered: leaf scans, leaf pictures with a white uniform background (referred as scan-like pictures) and leaf pictures in natural conditions (taken on the tree). The main originality of this data is that it was specifically built through a citizen sciences initiative conducted by Telabotanica, a French social network of amateur and expert botanists. This makes the task closer to the conditions of a real-world application: (i) leaves of the same species are coming from distinct trees living in distinct areas (ii) pictures and scans are taken by different users that might not used the same protocol to collect the leaves and/or acquire the images (iii) pictures and scans are taken at different periods in the year
Dataset
The task will be based on the Pl@ntLeaves dataset which focuses on 71 tree species from French Mediterranean area. It contains around 5436 pictures subdivided into 3 different kinds of pictures: scans (3070), scan-like photos (897) and free natural photos (2469). A detailed description of the data, with picture examples and the full list of species is available HERE. All data are published under a creative commons license.
Each image is associated with the following meta-data:
- date
- acquisition type: Scan, pseudoscan or photograph
- content type: single leaf, single dead leaf or foliage (several leaves on tree visible in the picture)
- full taxon name (species, genus, family…)
- French or English vernacular names (the common names),
- name of the author of the picture,
- name of the organization of the author
- locality name (a district or a country division or a regions).
- GPS coordinates of the observation
These meta-data are stored in independent xml files, one for each image. We provide here a set of 3 images (one of each type) and associated xml files :
997.jpg 997.xml
5379.jpg 5379.xml
2082.jpg 2082.xml
{kind=link}
{kind=link}
{kind=link}
Partial meta-data information can be found in the image's EXIF, and might include:
- the camera or the scanner model,
- the image resolutions and the dimensions,
- for photos, the optical parameters, the white balance, the light measures…
Task description
The task will be evaluated as a supervised classification problem with tree species used as class labels.
training and test data
A part of Pl@ntLeaves dataset will be provided as training data whereas the remaining part will be used later as test data. The training subset was built by randomly selecting 2/3 of the individual plants for each species (several pictures might belong to the same individual plant but cannot be split across training and test data).
- The training data finally results in 4004 images (2329 scans, 686 scan-like photos, 989 natural photos) with full xml files associated to them (see previous section for few examples). A ground-truth file listing all images of each species will be provided complementary. Download link of training data will be sent to participants on March 15th.
- The test data results in 1432 images (741 scans, 211 scan-like photos, 480 natural photos) with purged xml files (i.e without the taxon information that has to be predicted).
goal
The goal of the task is to associate the correct tree species to each test image. Each participant is allowed to submit up to 3 runs built from different methods. As many species as possible can be associated to each test image, sorted by decreasing confidence score. Only the most confident species will be used in the primary evaluation metric but we really encourage participants to provide an extended ranked list of species to allow us deriving meaningfull secondary statistics and metrics (e.g. recognition rate at other taxonomic levels, suggestion rate on top k species, etc.).
run format
Each run has to be provided as a single run file named as "teamname_runX.txt" where X is the identifier of the run (i.e. 1,2 or 3). The run file has to contain as much lines as the total number of predictions, with at least one prediction per test image and a maximum of 71 predictions per test image (71 being the total number of species). Each prediction item (i.e. each line of the file) has to respect the following format :
<test_image_name.jpg Genus_name species_name rank score>
the pair <Genus_name species_name> forms a unique identifier of the species. These strings have to respect the format provided in the ground-truth file provided with training set (i.e. the same format as the fields <Genus> and <Species> in the xml metadata files, see examples in previous section). <Rank> is the ranking of a given species for a given test image. For the primary evaluation metric (see below), only prediction items with Rank=1 will be considered. Other prediction items will be used for secondary metrics and statistics. <Score> is a confidence score of a prediction item (the lower the score the lower the confidence). Here is a fake run example respecting this format:
myteam_run1.txt
The order of the prediction items (i.e. the lines of the run file) has no influence on the evaluation metric, so that contrary to our example prediction items might be sorted in any way.
metric
The primary metric used to evaluate the submitted runs will be a classification rate on the 1st species returned for each test image. Each test image will be attributed with a score of 1 if the 1st returned species is correct and 0 if it is wrong. An average score will then be computed on all test images. A simple mean on all test images would however introduce some bias. Indeed, we remind that the Pl@ntLeaves dataset was built in a collaborative manner. So that few contributors might have provided much more pictures than many other contributors who provided few. Since we want to evaluate the ability of a system to provide correct answers to all users, we rather measure the mean of the average classification rate per author. Furthermore, some authors sometimes provided many pictures of the same individual plant (to enrich training data with less efforts). Since we want to evaluate the ability of a system to provide the correct answer based on a single plant observation, we also have to average the classification rate on each individual plant. Finally, our primary metric is defined as the following average classification score S:
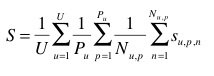
U : number of users (who have at least one image in the test data)
Pu : number of individual plants observed by the u-th user
Nu,p : number of pictures taken from the p-th plant observed by the u-th user
Su,p,n : classification score (1 or 0) for the n-th picture taken from the p-th plant observed by the u-th user
To isolate and evaluate the impact of the image acquisition type (scan, scan-like, natural pictures), an average classification score S will be computed separately for each type. Participants are allowed to train distinct classifiers, use different training subset or use distinct methods for each data type.
How to register for the task
ImageCLEF has its own registration interface. Here you can choose an user name and a password. This registration interface is for example used for the submission of runs. If you already have a login from the former ImageCLEF benchmarks you can migrate it to ImageCLEF 2011 here
___________________________________________________________________________________________________________________
Results
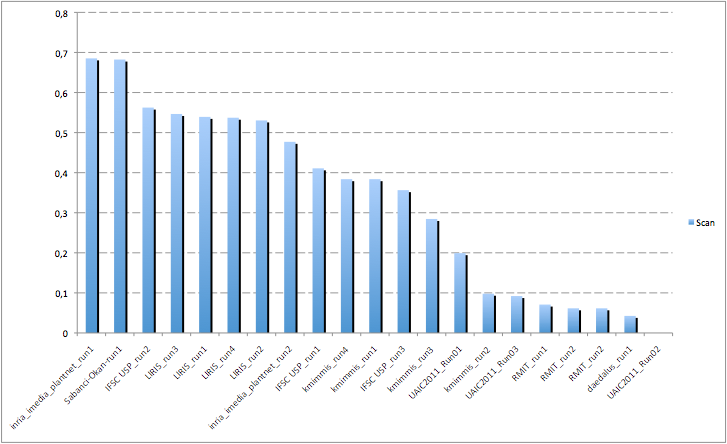
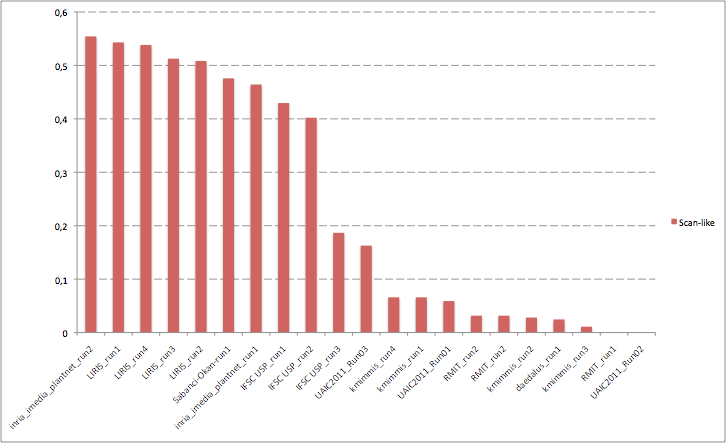
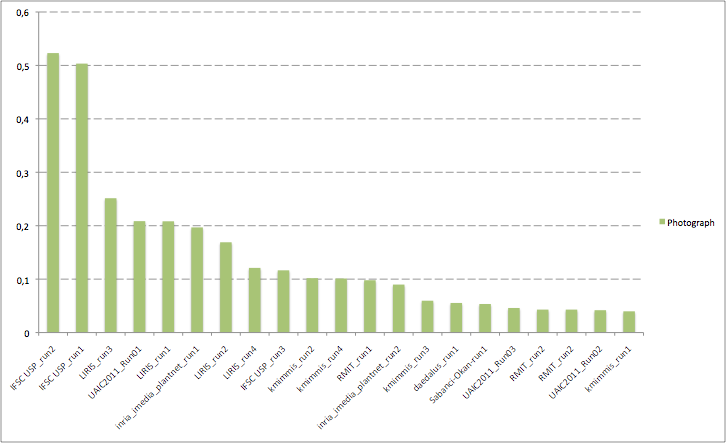
A total of 8 groups submitted 21 runs, which is a successful participation rate for a first year pilot task on a new topic. The following table and the three graphics the below present the normalized average classification score S obtained for each submitted run and each image type (scans, scan-like photos and photos). Click on the graphics to enlarge them. A last graphic presents the same results in a single graphic using histogram piles whose heights are computed by the mean of the 3 scores S. This gives an idea of the mean score over all image types while still keeping the relative performances on each image type. Additional statistics and comments on these results will be provided in the overview working note of the task published within CLEF 2011.
| Run | Scans | Scan-like | Photos | mean |
|---|---|---|---|---|
| IFSC USP_run2 | 0,562 | 0,402 | 0,523 | 0,496 |
| inria_imedia_plantnet_run1 | 0,685 | 0,464 | 0,197 | 0,449 |
| IFSC USP_run1 | 0,411 | 0,430 | 0,503 | 0,448 |
| LIRIS_run3 | 0,546 | 0,513 | 0,251 | 0,437 |
| LIRIS_run1 | 0,539 | 0,543 | 0,208 | 0,430 |
| Sabanci-Okan-run1 | 0,682 | 0,476 | 0,053 | 0,404 |
| LIRIS_run2 | 0,530 | 0,508 | 0,169 | 0,403 |
| LIRIS_run4 | 0,537 | 0,538 | 0,121 | 0,399 |
| inria_imedia_plantnet_run2 | 0,477 | 0,554 | 0,090 | 0,374 |
| IFSC USP_run3 | 0,356 | 0,187 | 0,116 | 0,220 |
| kmimmis_run4 | 0,384 | 0,066 | 0,101 | 0,184 |
| kmimmis_run1 | 0,384 | 0,066 | 0,040 | 0,163 |
| UAIC2011_Run01 | 0,199 | 0,059 | 0,209 | 0,156 |
| kmimmis_run3 | 0,284 | 0,011 | 0,060 | 0,118 |
| UAIC2011_Run03 | 0,092 | 0,163 | 0,046 | 0,100 |
| kmimmis_run2 | 0,098 | 0,028 | 0,102 | 0,076 |
| RMIT_run1 | 0,071 | 0,000 | 0,098 | 0,056 |
| RMIT_run2 | 0,061 | 0,032 | 0,043 | 0,045 |
| RMIT_run2 | 0,061 | 0,032 | 0,043 | 0,045 |
| daedalus_run1 | 0,043 | 0,025 | 0,055 | 0,041 |
| UAIC2011_Run02 | 0,000 | 0,000 | 0,042 | 0,014 |
Mean results over all image types:

_____________________________________________________________________________________________________________________
Schedule
- 31.01.2011: registration opens for all CLEF tasks
- 15.03.2011: training data release
- 01.05.2011: test data release
- 15.05.2011: registration closes for all ImageCLEF tasks
- 15.06.2011: submission of runs
- 30.07.2011: release of results
- 14.08.2011: submission of working notes papers
- 19.09.2011-22.09.2011: CLEF 2010 Conference, Amsterdam, The Netherlands.
_____________________________________________________________________________________________________________________
Contacts
Hervé Goeau (INRIA-IMEDIA): herve(replace-that-by-a-dot)goeau(replace-that-by-an-arrobe)inria.fr
Alexis Joly (INRIA-IMEDIA): alexis(replace-that-by-a-dot)joly(replace-that-by-an-arrobe)inria.fr
| Attachment | Size |
|---|---|
| 50.02 KB | |
| 26.53 KB | |
| 25.55 KB | |
| 53.31 KB |
{kind=link}
{kind=link}
{kind=link}
{kind=link}